Operating System
From Demon to OS
Maxwell’s Demon works. It reads the partition, classifies each molecule, and operates the trapdoor accordingly. The second law is not violated locally — it is suspended, at the cost of the Demon’s continuous presence and judgment. A harness engineer does the same thing: observe the context, filter noise, control what information enters. Structurally, it is the same job.
But the Demon scales to exactly one door.
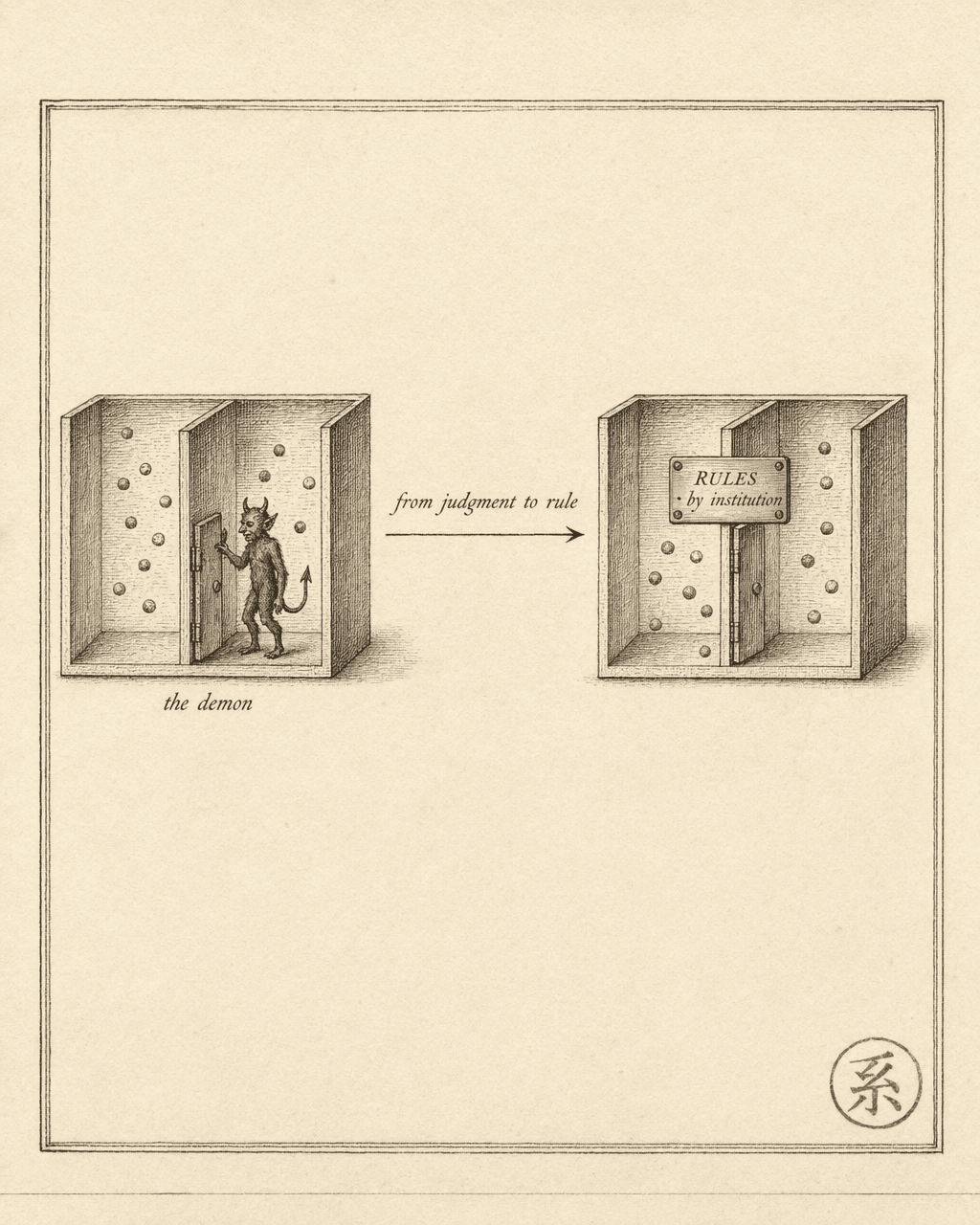
One Demon, one judgment at a time. No rules, no fallback when it is absent, no audit trail when it makes a mistake. This is not an implementation problem — it is the structural ceiling of the case-by-case judgment pattern. You cannot have one Demon per tool call.
Write the sorting rules down as policy, and you have an operating system.

Karpathy’s three-year refinement
In 2023, Andrej Karpathy described LLMs as “the kernel process of an emerging operating system.” The phrase stuck. It captured something intuitively right about the relationship between language models and the broader computational infrastructure forming around them.
Three years later, he made the intuition precise. In a 2026 exchange on X:
LLM = CPU (dynamics: statistical and vague not deterministic and precise) Agent = OS kernel (the “smartest” process managing resources and coordinating other processes) Harness = OS (the full system with all its components, policies, abstractions)
The 2026 version does not invalidate the 2023 intuition — it resolves it into structure. The 2023 observation was holistic: something OS-like is emerging around LLMs. The 2026 version decomposes that intuition into three distinct layers with distinct roles.
The decomposition matters because it changes what you look for. Once you see the three layers separately, the questions become specific: what does memory management look like when RAM is a context window? What does scheduling look like when a CPU call costs money? What does a trust boundary look like when the CPU itself can be “persuaded” by language?
The three-layer mapping
| OS Layer | Agent System | Core Property |
|---|---|---|
| CPU | LLM | Statistical and vague, not deterministic and precise |
| OS kernel | Agent | Manages resources, coordinates processes |
| Full OS | Harness | All components, policies, abstractions |
The architectural relationship is preserved across the mapping. The CPU executes instructions; it does not decide what to execute. The kernel orchestrates resources, schedules processes, enforces boundaries — it is the decision layer above the execution layer. The full OS wraps everything: memory subsystems, scheduling algorithms, permission models, inter-process communication, all the accumulated engineering that makes the hardware usable.
An LLM executes tokens. It does not decide what task to work on, which tools to call, when to stop, or how to allocate a budget. An agent — specifically the orchestrating logic — does that coordination. The harness is the full system: context management, task scheduling, trust enforcement, collaboration protocols.
The analogy is not decorative. OS engineers spent fifty years solving problems that agent engineers are encountering now, in slightly different shapes. Every design intuition buried in OS architecture — why preemptive scheduling beats cooperative, why virtual memory beats manual allocation, why least-privilege is worth its complexity — came from painful failures. That accumulated intuition does not need to be re-earned from scratch.
Where “statistical and vague” changes everything
Karpathy’s one-sentence CPU definition does something subtle. It does not just say “LLM is like a CPU.” It specifies the exact dimension where the analogy holds and exactly where it breaks. The dynamics are statistical and vague, not deterministic and precise.
An OS kernel trusts its CPU implicitly. The CPU executes whatever instruction sequence it receives. It does not understand the instructions. It cannot be convinced to ignore a segment fault or escalate privileges through a well-crafted argument. The hardware barrier between user mode and kernel mode is enforced by the physics of the chip, not by the CPU’s willingness to cooperate.
An agent’s CPU is different. The LLM is the system that reads all inputs — including inputs that might be deliberately crafted to alter its behavior. There is no type system, no instruction validator, no hardware mechanism that distinguishes instructions from data. Natural language is the interface, and natural language has no equivalent to a segment fault. This single property cascades into every design decision: memory management cannot just track what is present, it must track what is accurate. Scheduling cannot just detect process termination, it must judge semantic completion. Trust boundaries cannot rely on hardware enforcement, they must be layered architecturally.
Four OS abstractions, each worth fifty years of refinement, each needing adaptation for a probabilistic CPU — and each breaking at a precise point that reveals something the OS never had to solve.
The most immediate constraint in any agent system is also the most visible: the context window. Everything the LLM “knows” at inference time has to fit there. How OS engineers solved the analogous problem — infinite logical memory from finite physical memory — is where the story begins.
Further reading
- Karpathy, A. (2023). Intro to Large Language Models. YouTube. (“the kernel process of an emerging operating system”)
- Karpathy, A. (2026-03-31). Reply to @gvanrossum. X. (The three-layer decomposition: LLM=CPU, Agent=kernel, Harness=OS)
The Memory Hierarchy
The context window’s finite size is not a temporary engineering limitation that will disappear as models scale. It is a new instance of a very old problem, one that operating systems solved decades ago.
Why storage is always a pyramid
Fast storage is expensive. Cheap storage is slow. This is not a historical accident; it is a fundamental constraint rooted in physics and economics, and it has held across every technology generation from magnetic cores to DRAM to SSDs to NVMe.
The numbers make the tradeoff vivid. CPU registers hold data in under a nanosecond — but there are only a handful of them, measured in kilobytes; one extra byte and the register file is full. L1 cache stretches to a few megabytes at two or three nanoseconds. RAM sits at a hundred nanoseconds but buys you tens of gigabytes. A disk takes milliseconds, but terabytes are suddenly affordable. The pattern has held across every storage technology from magnetic cores to NVMe: each layer down is an order of magnitude slower and an order of magnitude larger. That ratio has never broken.
Computer architects learned to exploit a statistical property of programs to make this hierarchy work: locality. Programs tend to access the same data repeatedly in short windows of time (temporal locality), and they tend to access data that is physically near data they just accessed (spatial locality). If you keep the recently-used, frequently-used data in the fast layer and push everything else to the slow layer, average access time approaches the fast tier’s speed.
Virtual memory is the elegant abstraction built on top of this observation. The operating system presents each process with a continuous, large address space — a fiction. Behind the scenes, it maps the most actively used portions of that address space to physical RAM and stores the rest on disk. When a process reaches for a page that is not in RAM, the hardware fires a page fault: execution pauses, the OS retrieves the needed page from disk, evicts the least-recently-used page to make room, and resumes execution. The process never sees any of this. The mechanism is invisible — transparent in the systems sense.
The agent memory pyramid
The same structure maps directly onto agent systems:
| OS Memory Layer | Agent System Equivalent | Who manages it |
|---|---|---|
| CPU cache (KV cache) | KV cache — inference acceleration | Inference infrastructure, automatic |
| RAM | Context window | Harness — the core management object |
| Disk | Vector database / external storage | Harness — explicit management |
| Network storage | External APIs / knowledge bases | Agent — on-demand retrieval |
The core problem is identical: simulate unlimited slow storage access using a finite fast store. The context window is RAM — limited in size, but directly accessible during inference. Vector databases are the disk — large, but every retrieval is an explicit operation with measurable latency.
Virtual memory in agent systems
UC Berkeley’s MemGPT (2023) made this mapping explicit as a system design. Main context is RAM: whatever the LLM can access directly during inference. Archival memory is disk: an external store for history, documents, and prior reasoning that does not fit in context. When the agent needs something from archival memory, it generates a function call to retrieve it — the agent’s version of a page fault. When context approaches its limit, summaries are compressed and written back to external storage — the agent’s version of page eviction.
Structurally, this is the same design pattern: finite fast storage simulating access to a larger slow store. The underlying mechanism is recognizably analogous.
But there is one dimension where the analogy inverts, and it is worth being precise about it. An OS page fault is completely transparent to the running process. The hardware detects the missing page, the OS handles the swap, and execution resumes — the process never knew anything happened. MemGPT’s “page fault” is the opposite: it is an active function call that the LLM itself generates, after the LLM decides that it needs to retrieve something and chooses what to retrieve. The LLM is not a passive recipient of memory management. It is the system making the decisions. Resource management transparency is inverted, not just translated.
This inversion is not a design flaw — it is a structural consequence of building on a language model. The LLM is the thing best positioned to judge “what information do I need right now?” No external system can make that semantic judgment on its behalf. The design adapts the mechanism while preserving the underlying purpose.
Anthropic’s Compaction API takes the MemGPT approach and descends it into production infrastructure. When context nears its limit, the API server automatically summarizes and compresses the conversation, produces a compact block, and continues from the compressed state. Application code does not need to implement the paging logic manually. This follows a familiar OS trajectory: a research mechanism that worked gets embedded in infrastructure so that every application benefits without reimplementing it.
The breakpoint: wrong context is worse than missing context
OS virtual memory has one deeply reliable property: it only affects latency, never correctness. The data on disk is an exact copy of what was in RAM. Retrieving a page introduces a delay — sometimes a significant one — but the retrieved data is bit-for-bit accurate. A process running after a page fault behaves identically to one that never triggered it. Correctness is preserved.
Agent memory retrieval breaks this guarantee.
If a vector database retrieval returns context that is semantically related but factually wrong, the effect is not just a slowdown. The wrong context actively degrades reasoning quality. Chroma’s 2025 research across eighteen frontier models — including GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 — measured this directly: distractor interference, where a retrieved passage is topically relevant but incorrect, harms model performance more than providing no context at all. The model cannot easily reject a plausible-sounding but wrong piece of context; it gets incorporated into the reasoning.
An OS memory manager only has to track whether a page is present. An agent memory manager has a second dimension: whether the retrieved content is accurate and appropriate. This is a new engineering requirement with no direct OS equivalent.
Longer windows do not eliminate management
A natural response is to wait. If context windows keep growing — and they are, from four thousand tokens to one million — won’t management become unnecessary?
RAM capacity has grown from megabytes to hundreds of gigabytes over the history of computing. Virtual memory did not disappear. It became more sophisticated: larger page tables, NUMA-aware allocation, prefetching algorithms, huge pages to reduce TLB pressure. The management layer did not shrink because the resource grew; it expanded to manage the new scale.
The same dynamic applies here. Chroma’s data shows performance degradation as input length increases, consistently across models. The cause is not an insufficient window size. It is that attention is scarce: a fixed computational budget gets spread over more tokens, diluting the signal from any individual piece of information. A longer window holds more, but it also dilutes more. The signal-to-noise problem does not go away; it scales with the resource.
Management complexity grows with system complexity, not in inverse proportion to raw capacity.
Memory management answers “what does the LLM get to work with.” A different question is who gets to use the LLM at all, and when. Multiple agents sharing a single inference backend need arbitration — and that is the job OS engineers have always called scheduling.
Further reading
- Packer, C. et al. (2023). MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560.
- Chroma. (2025). Context Rot: How Long Contexts Degrade LLM Performance. research.trychroma.com.
- Anthropic. (2026). Context Management. docs.anthropic.com. (Compaction API)
Scheduling
Scheduling solves an ancient problem: multiple claimants, one scarce resource, who goes first, for how long, and who takes over after.
Operating systems have been solving this problem for fifty years.
A brief history of OS scheduling
The earliest systems had no scheduling at all. Programs ran sequentially — one completed before the next could start. CPUs sat idle during IO operations. The utilization reports from that era read like an apology letter.
Round-robin was the first real breakthrough: assign each process a fixed time slice, preempt when it expires, move to the next. CPU utilization climbed. Then the obvious problem surfaced — a real-time alarm process and a background log-compression job get the same time slice, regardless of urgency. Equal by clock, wrong by design.
Priority scheduling fixed that intuition and introduced a different pathology: if high-priority processes never stop arriving, low-priority processes wait indefinitely. A theoretically correct mechanism that could permanently strand real work. Systems running production priority schedulers accumulate “starved” processes the way a cluttered desk accumulates papers at the bottom of the pile.
Linux’s Completely Fair Scheduler changed the question from “who has higher priority?” to “who has been most shorted?” Track how much CPU time each process has been owed, prioritize the most-owed process first. The fairness definition shifted from “equal slices” to “equal debt clearance” — a subtler and more defensible contract. cgroups added budget enforcement on top: each process group gets a maximum CPU allocation and gets throttled when the budget runs out.
Fifty years of scheduling evolution, driven almost entirely by the failures of the preceding approach. Each breakthrough was bought by a real system that misbehaved in production.
Harness scheduling, dimension one: orchestration decisions
In agent systems, scheduling at the harness layer is not about which inference request enters the GPU queue first (that is a separate problem at the inference infrastructure layer, operating below and orthogonally to what harness engineers control). Harness scheduling is about which tasks get executed, in what order, and whether to run them in parallel — the orchestrator’s core responsibility.
The mapping onto OS scheduling modes is direct:
| OS Scheduling Mode | Agent Orchestration Equivalent | Core Decision |
|---|---|---|
| Batch processing | Sequential task chain | Strict serial execution, dependency guaranteed |
| Round-robin | Multi-agent turn-taking (GroupChat) | Fair rotation, prevents any one agent from monopolizing |
| Priority scheduling | Hierarchical delegation (primary → sub-agent) | High-value tasks get resources first |
| Preemptive interrupt | Event-driven interrupt (LangGraph interrupt) | Critical conditions pause current execution |
| Peer-to-peer | Agent teams | Decentralized, task self-organization |
The range of orchestration patterns in active use — from strict sequential pipelines to fully decentralized teams — covers a scheduling design space that closely parallels OS history. Different workloads call for different modes; the tradeoffs are structurally familiar.
Harness scheduling, dimension two: cost ROI
Here is where agent scheduling diverges from the OS model in a way that matters.
The OS cgroups question is: “How much CPU can this process group consume?” CPU time is an internal cost — the system tracks and enforces it, but it is not priced per unit to the application. The accounting is real; the billing is not.
The harness question is: “How many tokens is this task worth spending?”
Tokens are explicitly and immediately priced. Every inference call produces a visible, attributable cost. This changes the scheduling objective function at a structural level: not just “can this resource complete the task?” but “is completing this task worth what it costs at this model tier?”
OS schedulers never had to ask that second question. CPU time is an internal accounting entry, not a per-decision bill. The cost of running a low-priority batch job is diffuse and shared. Token cost is exact and immediate.
That difference permeates every scheduling decision: task priority now has two dimensions — urgency and quality-per-token expectation. Model routing is no longer “use the strongest available” but “does this step’s precision requirement justify the per-call cost differential?” Task cutoff is no longer a simple timeout but an expected-value calculation — at what point does the marginal token cost of continuing exceed the marginal probability of a better result?
OS scheduling optimizes for throughput and fairness. Harness scheduling must also optimize for quality-per-cost — a ratio OS schedulers never computed because CPU time was never billed per judgment call.
This is genuinely new engineering territory. Token budget management has a structural analogue in cgroups, but the objective is different enough that the design patterns do not transfer directly. How to set token budgets, how to route tasks to models of varying cost and capability, when to cut losses on a failing agent — these questions have no fifty-year-old answers waiting to be borrowed.
The breakpoint: semantic termination
OS scheduling has reliable termination signals. A process runs to completion and exits. The exit code is non-zero if something went wrong. Time can serve as a fallback termination condition — a watchdog kills anything that has not finished by its deadline. These signals are precise, unambiguous, and machine-checkable.
Agent scheduling encounters a problem that OS scheduling never had to confront: “done” is a semantic judgment, not a machine state.
Consider this illustrative scenario: an editing agent reviews a document and annotates it with “the tone needs to be more professional.” A writing agent revises accordingly and returns the document. The editing agent responds: “better, but now it’s too dry — it needs more energy.” Both agents are working. Both are consuming tokens. The system is not converging.
This is not a deadlock — no one is blocked waiting for anyone else. It is a livelock: sustained activity, zero progress, and the bill accumulating. An OS timeout can detect it; an OS scheduler has no concept of whether the activity is making semantic progress. The exit condition for “the document is good enough” is not a time or a state machine — it is a judgment about quality that requires understanding what “good” means in context.
AgenticOS Workshop (ASPLOS 2026) lists semantic-aware scheduling as a core research problem precisely because this is where the OS toolbox runs out. Timeout is a rough proxy: not “is the result satisfactory?” but “has too much time passed?” More precise solutions may require explicit goal-state definitions written into the agent’s initialization logic — making “what counts as done” a first-class engineering artifact rather than an implicit assumption.
Scheduling is orthogonal to model capability
Stronger CPUs did not eliminate the Completely Fair Scheduler. Cheaper disk did not eliminate virtual memory. The OS resources scaled, and so did the management systems built on top of them.
Stronger LLMs do not eliminate the harness scheduling problem — they make it more demanding in both dimensions. A more capable model can accept more complex tasks, which means more agent collaboration and higher-dimensional orchestration decisions. A more capable model typically commands higher pricing, which means the cost ROI calculus matters more, not less.
The scheduling design space is orthogonal to inference capability. It does not shrink as the models improve.
Scheduling determines who runs and when. Trust boundaries determine what they can do when they do run — which tools they can call, which data they can see, and what happens when something tries to exceed its authorization.
Further reading
- Mei, K. et al. (2025). AIOS: LLM Agent Operating System. COLM 2025. arXiv:2403.16971. (System-layer LLM inference scheduling — FIFO/RR implementation, orthogonal to harness-layer scheduling)
- AgenticOS Workshop. (2026). 1st Workshop on OS Design for AI Agents. ASPLOS 2026. (Semantic-aware scheduling, AgentCgroup token budget management)
- Anthropic. (2026). Building Agents with the Claude Agent SDK. claude.com/engineering.
Trust Boundaries
An operating system does not trust the programs it runs.
This is not a cynical design choice — it is the only defensible starting point. User programs may contain bugs. They may be compromised by attackers. They may be outright malicious. The OS assumes worst-case behavior and limits the blast radius through two independent mechanisms: permissions (what a program is allowed to do) and resource isolation (what a program is allowed to see). One without the other is half a defense: permissions without isolation let programs read any accessible data, while isolation without permissions lets programs do anything they want with visible data.
Harness engineering faces the identical structural problem and has been independently reinventing both mechanisms.
Permissions: the tool call as system call
An operating system’s system call interface is the only legitimate entry point through which a user program can access privileged resources. A program cannot directly manipulate hardware, network stacks, or file systems — it can only request the kernel to perform operations on its behalf, and the kernel checks permissions before acting.
The structure in agent systems is identical. An agent cannot directly send email, modify a database, or execute shell commands. It can only request the harness to perform those operations through a tool call, and the harness checks authorization before acting. The system call is the tool call.
Production agent systems are already reinventing this structure. The core design principle mirrors OS security: deny takes precedence over allow. Rejection always outranks permission, and a deny rule set at any scope cannot be overridden by a more permissive rule at a lower scope.
Permission modes form a spectrum from fully manual confirmation to fully automatic execution — just as OS trust levels range from unprivileged user mode through root. The scope hierarchy is layered in the same architectural spirit as ring protection: organizational policy overrides project configuration, project configuration overrides user preferences, and deny is unidirectional. Ring 0 constraints are invisible to ring 3 code; a top-level deny is invisible to lower-level allow rules.
The breakpoint: this CPU can be persuaded
An OS process cannot be “convinced” to violate its permission boundaries.
A process does not understand what it is executing. It runs binary instructions. You can inject malicious code, but even injected code operates within the OS permission system — it runs under the same user identity, with the same syscall constraints. Hardware enforcement is physics, not policy.
A carefully crafted prompt injection does not need to find a code vulnerability or escalate privileges through a system call. It needs only to cause the agent to exhibit behavior that violates its authorization boundaries — through whatever mechanism (instruction following, context hijacking, or something else), the observable effect is the same: the agent does something it was not supposed to do. There is no type system, no compiler, no mechanism equivalent to “this instruction is invalid.” The permission boundary is architecturally enforced; the attack surface is semantic.
In an OS, you trust the kernel’s logic and need not trust the CPU itself — the CPU is deterministic execution hardware. In an agent system, this assumption fails: the LLM is simultaneously the execution engine and the system that interprets inputs, and inputs can be attack vectors.
Execute-Only Agents (ASPLOS 2026, Tiwari & Williams) proposed a structural response: separate the planning layer from the execution layer into two distinct security domains. The execution layer receives only pre-approved operation specifications, not natural language instructions. A component that cannot be convinced by language is a genuine security boundary — not a patch on the permission system, but an architectural elimination of the attack surface.
Resource isolation: data visibility layers
OS file system permissions stratify data into three visibility tiers through ownership and mode: kernel-exclusive data (/proc, /lib — user processes read-only or invisible), system-managed shared resources (/etc — controlled write access), and user-private space (~/ — full read-write). The design principle across all three tiers is the same: entities at different trust levels see different data, and write permissions increase strictly with trust level.
Agent systems face the same layering requirement. Immutable platform foundations (base configuration, built-in capabilities) are read-only to agents. Cross-session shared state (global configuration, shared knowledge) is writable only through controlled interfaces. The current session’s workspace belongs entirely to that session. This three-tier structure is isomorphic to the OS file system — not by coincidence, but because the same constraints (multi-tenancy, least privilege, audit requirements) drive the same solution.
OS engineers also perfected a strategy for efficient initialization across these tiers: fork() Copy-on-Write. Parent and child processes share the same physical pages; only when a process writes does the OS create a private copy. Agent session initialization can apply the same principle — shared-layer data is not bulk-copied at startup, but copied on demand when the agent needs to modify something. Defer allocation until a write actually happens; avoid unnecessary duplication at initialization.
Defense in depth
The two mechanisms address different threat surfaces, and that complementarity is the point.
Permission enforcement prevents agents from doing the wrong thing — calling unauthorized tools, executing disallowed operations. Resource isolation prevents agents from seeing the wrong data — accessing information outside their scope, contaminating shared state.
When prompt injection bypasses the permission system, resource isolation is the second line of defense. When resource isolation is misconfigured, the permission system is the first line of defense. The two work together without depending on each other’s perfection. This is defense in depth, not single-point protection.
Trust boundaries answer the question of what an agent can do when working alone. When agents need to collaborate — with humans, with other agents — the trust boundaries between them need communication channels. That is the next problem.
Further reading
- Anthropic. (2026). Claude Code: Permissions. code.claude.com/docs/en/permissions. (Six permission modes, deny-first rule hierarchy, scope hierarchy)
- AgenticOS Workshop. (2026). Execute-Only Agents; Grimlock: eBPF-based Agent Monitoring. ASPLOS 2026.
- OpenAI. (2025). Unrolling the Codex Agent Loop. openai.com/engineering. (Independent sandboxing, network-off-by-default in production)
Cooperation Protocols
Isolation creates safety. It also creates islands.
Two processes cannot directly read each other’s memory — that is the trust boundary design working correctly. IPC exists precisely because the OS needed to maintain process isolation while still allowing processes to communicate. The solution it arrived at is precise: pipes, message queues, shared memory, sockets. One defining property across all of them: byte-exact. Whatever process A sends, process B receives, without a single bit changed.
Agent systems have two fundamentally different collaboration modes: human-agent (a human delegates to an agent) and agent-agent (agents communicating with each other). Both share the same break from the OS model, but the break happens at different points.
Human-agent: indirect delegation via ACI
An operating system translates user intent into hardware operations. The user clicks “Save.” The OS converts that click into a sequence of IO system calls — buffer flush, file system metadata update, disk write. The translation chain is precise: a user action, captured as a deterministic GUI event, becomes a typed API call, reaches hardware unchanged.
An agent performs the same translation, but the medium is different.
The user says “help me clean up this report.” The agent translates that into a sequence of tool calls — read file, analyze structure, reorganize sections, output result. The translation chain starts with natural language, not a typed API call.
ACI — Agent-Computer Interface — is the interface design discipline for this translation chain. Anthropic’s work on SWE-bench agents found that the time spent optimizing tool interfaces exceeded the time spent optimizing prompts. Tool names should be self-explanatory. Error messages should be interpretable by the model. Parameter design should prevent predictable classes of mistakes — forcing absolute paths over relative ones, for example, eliminates a category of systematic errors that arise when an agent loses track of its working directory.
ACI is the system call interface design discipline applied to agents: design from the LLM’s perspective, the way OS engineers once designed syscall APIs from the programmer’s perspective. The structural difference is not in the design process but in the medium — one side is type-safe function signatures, the other is natural language.
Karpathy framed the broader direction in 2025: “make infrastructure actively adapt to LLMs” — websites offering llm.txt alongside HTML, documentation shipped as plain markdown rather than rendered pages. This extends ACI from individual tool interfaces to the entire infrastructure layer. The aim is not to make LLMs better at reading human-designed interfaces; it is to redesign the interfaces so that LLMs can use them directly.
The breakpoint in the human-agent chain is intent interpretation uncertainty. “Clean up the report” is ambiguous: preserve the original meaning and reformat, or rewrite for clarity, or reduce length by half? The OS equivalent — “save the file” — is a deterministic API call with no interpretation space. An agent’s starting point is different. The user’s intent is expressed in natural language; the agent’s execution is discrete and specific; the mapping between them is probabilistic. This is not a solvable engineering problem in the way that byte-accurate transmission is solvable. It is a structural property of natural language as an interface medium.
Agent-agent: direct communication via A2A
Inter-process communication in an OS is symmetric: two processes are both processes under the same OS, using the same IPC mechanisms on equal terms.
Agent-to-agent communication is less symmetric. Agents built on different frameworks, in different languages, deployed by different organizations — how do they communicate?
Google’s Agent-to-Agent protocol (A2A, April 2025) is the first serious attempt at standardization. Three core components:
- Agent Card: each agent publishes a capability declaration (JSON) describing what it can do and what communication patterns it supports — analogous to
/procentries in a file system, letting callers discover at runtime what a counterparty is capable of - HTTPS + JSON-RPC: a deterministic transport layer with a unified message format, using mature web infrastructure rather than inventing a new network protocol
- OAuth authentication: identity verification for cross-organization agent communication, answering the question “how do I know who I’m talking to?”
What A2A is doing structurally resembles what TCP/IP did: taking fragmented, private, framework-local communication into a cross-implementation standard. Different OSes could then talk to each other. Different agent frameworks can now talk to each other.
The breakpoint: no semantic checksum
OS IPC is byte-exact. The A2A transport layer can also be byte-exact. But the breakpoint in agent communication is not at the transport layer.
Agent A generates a summary and sends it to Agent B. That summary is Agent A’s lossy compression of the original information: A retained what it judged important and discarded what it judged peripheral. But A’s judgment is probabilistic. B reasons from that summary, potentially discarding further detail, potentially shifting semantics. The longer the chain, the more cumulative drift — what arrives at agent D may bear only a family resemblance to what started with agent A.
An OS process can send 1024 bytes through a pipe and the receiver can verify data integrity with a CRC or hash. Agent communication has no equivalent mechanism for semantic content — no “semantic integrity check,” no way to confirm that B understood what A intended to express.
The problem exists in both collaboration modes, but through different mechanisms:
- Human-agent: ambiguity introduces interpretation divergence when the user’s intent is translated into agent actions
- Agent-agent: compression introduces information loss when an agent’s output is passed to the next agent
A2A wraps natural language content in a deterministic protocol (HTTPS/JSON-RPC), reducing transport-layer loss. It cannot eliminate semantic-layer decay: the natural language content inside the messages is still lossy, and the protocol layer has no mechanism for verifying semantic fidelity. Structured message formats — JSON schemas that constrain specific fields rather than permitting free text — reduce the decay, but agents often need to pass inherently unstructured judgments and reasoning that cannot be fully structured.
This is the signal-channel noise from the entropy chapter instantiated in a cooperation chain: natural language has no error-correcting code. Every transmission is a lossy semantic transform.
Communication complexity is orthogonal to model capability
Stronger processes did not eliminate the need for IPC — they still needed to communicate with other processes, still needed to call system resources.
Stronger LLMs do not eliminate the need for cooperation protocols. A more capable model can handle more complex tasks, and more complex tasks typically require more agent collaboration — more human-agent delegation chains, more agent-agent communication hops. Communication complexity scales with task complexity; model capability improvements do not reduce it.
The protocol design space is orthogonal to inference capability.
Each pillar cracked at a specific point. Those cracks, assembled together, are not random — they point in a consistent direction.
Further reading
- Google. (2025). Agent2Agent Protocol (A2A). a2aproject.github.io.
- Anthropic. (2025). Building Effective Agents. anthropic.com/engineering. (ACI principles: design tool interfaces from the model’s perspective)
- Karpathy, A. (2025). Software Is Changing (Again). YC AI Startup School. (ACI extended to infrastructure: llm.txt, Docs for LLMs)
- Factory.ai. (2025). Evaluating Context Compression for AI Agents. (Empirical measurement of information decay)
Where the Analogy Breaks
Exact break points are more useful than vague similarities.
Assembled together, the cracks across four pillars are not random design problems. They point in a consistent direction — and that direction is more informative than any of the individual similarities.
Six break points
| Dimension | OS | Agent Harness | Engineering consequence |
|---|---|---|---|
| CPU trustworthiness | Processes don’t understand what they execute; they can’t be argued into privilege escalation | LLM can be caused to exhibit out-of-bounds behavior by natural language inputs | Trust boundaries must extend to the CPU layer (Execute-Only) |
| Page fault cost | Adds latency only; retrieved data is bit-accurate | May add errors (distractor interference) | Memory management is not only “is it present?” but “is it correct?” |
| Termination condition | Time elapsed or exit code — deterministic signals | ”Done” is a semantic judgment | Requires semantic termination conditions; OS toolbox has none |
| Communication fidelity | Byte-exact, checksum-verifiable | Natural language; no semantic checksum | Every transmission is a lossy transform; structured formats reduce but don’t eliminate decay |
| Determinism | Same input → same output | Same input → variable output (temperature parameter) | Tests cannot rely on exact assertions; statistical validation required |
| Identity stability | PID cannot be altered by user-mode programs | System prompt can be rewritten by injection | Agent identity is an open problem; cryptographic signing approach not yet mature |
These six break points share a single common root: the OS CPU is deterministic execution hardware; the agent CPU is a statistical language model. Karpathy’s 2026 definition — “LLM = CPU (dynamics: statistical and vague not deterministic and precise)” — embeds this distinction directly into the analogy itself.
Breaks are not failures — they are landmarks
Each break point marks a design space that the OS paradigm has not covered:
CPU trustworthiness → Execute-Only Agents is one direction: separate the language understanding layer from the execution layer into distinct security domains, so the execution layer cannot be convinced by language. Hardware-attested execution is another direction: cryptographic proof that a code segment ran as intended. Both are active research areas without mature industrial answers.
Page fault cost → Semantics-aware memory management: not just LRU (least recently used), but also information quality. “Is this historical record still valid?” and “How recently was this record accessed?” are two independent dimensions. Current context management tooling primarily addresses the second.
Termination condition → AgenticOS Workshop named this a core research problem. Timeout is a coarse proxy: not “is the result satisfactory?” but “has too much time elapsed?” More precise solutions may require explicit goal-state definitions written into agent initialization — making “what counts as done” a first-class artifact — or convergence detection as an automatic heuristic.
Communication fidelity → Structured protocols (A2A’s JSON-RPC) wrap non-deterministic semantics in a deterministic transport layer. A further direction: explicitly tagging critical information to distinguish “facts” (cannot be dropped by summarization) from “context” (lossy compression acceptable).
Determinism → Traditional software testing rests on a premise: same input, same output. Hard-code the assertion, CI goes green, ship it. When the CPU is statistical, that premise vanishes — the same prompt run twice may yield structurally different responses. Testing strategy must shift from exact matching to statistical validation: sample multiple runs, replace string equality with semantic similarity, replace hard-coded assertions with LLM-as-judge. “Pass” is no longer binary; it is a confidence interval.
Identity stability → The most open problem. Grimlock (ASPLOS 2026) uses eBPF at the kernel layer to monitor agent behavior, providing observability but not resolving system prompt integrity. Cryptographic signing of system prompts — analogous to code signing — is a theoretical direction; practical challenges remain unsystematized.
What transfers, and what does not
OS engineers accumulated fifty years of design intuition about scheduling, memory, isolation, permissions, and communication. Why preemptive scheduling outperforms cooperative scheduling across most workloads. Why virtual memory is superior to manual physical memory management. Why the principle of least privilege is worth the complexity it introduces.
These intuitions are not abstract principles. They are backed by specific failure cases, by experimental data, by precise quantification of engineering costs. They were learned painfully. They are not available purely by reasoning from first principles — they required failure to generate.
When a harness engineer faces the question “multiple agents competing for LLM inference resources — how do I arbitrate?” they do not need to explore the design space from scratch. OS scheduling history already tells them that batch processing is sufficient but wastes CPU, that round-robin is fairer but incurs switching overhead, that priority scheduling risks starvation. These design intuitions transfer directly, without requiring new failure cases to accumulate.
The analogy gives the engineer a map — they know what tools to bring into a new design space. The break points tell the engineer where the map stops being accurate and original cartography begins.
Four lenses, one system
This chapter is the fourth lens.
Orthogonality gave the decomposition: model capability and harness engineering are orthogonal forces. Investment in directions orthogonal to model capability does not get erased by model iteration.
Cybernetics gave the skeleton: the observer-controller-plant triangle, requisite variety constraints, feedback loop topology. Harness engineering is control system design.
Entropy gave the dynamics: why systems tend toward degradation without active maintenance, why sorting information has irreducible costs, why Maxwell’s Demon cannot scale.
Operating systems (this chapter) gave the institutions: translate the Demon’s individual judgments into rules, translate the cybernetic structure into four engineerable pillars, translate entropy management from intuition into a system with available tools. The four pillars — memory management, scheduling, trust boundaries, cooperation protocols — and the six break points are dimensions of the same framework, not independent engineering problems.
The four lenses together make the harness’s structure legible: not just a force in the right direction, not just a feedback loop, not just an entropy-fighting mechanism, but a complete operating system — with memory, scheduling, trust boundaries, and communication protocols — running on a CPU that is probabilistic, that processes natural language as instruction, and that makes every OS abstraction need rethinking from its root assumptions.
Maxwell’s Demon reads state, makes judgments, maintains order. The OS institutionalized that work. Harness engineers are reinventing the OS — this time, with a probabilistic CPU.
Further reading
- AgenticOS Workshop. (2026). 1st Workshop on OS Design for AI Agents. ASPLOS 2026. (Six break points and their research frontiers: Execute-Only, semantic scheduling, Grimlock)