Cybernetics
The helmsman
An agentic system’s output is the resultant of two forces — model capability and everything you do at the harness layer. Orthogonality tells you where to aim. But what is the actual mechanism of “aiming”? What kind of work is your harness doing?
In 1948, a mathematician gave that work a name.
The word cybernetics comes from the Greek κυβερνήτης — helmsman. Not a philosopher, not an architect. A helmsman. Someone adjusting course in real time, against wind and current.

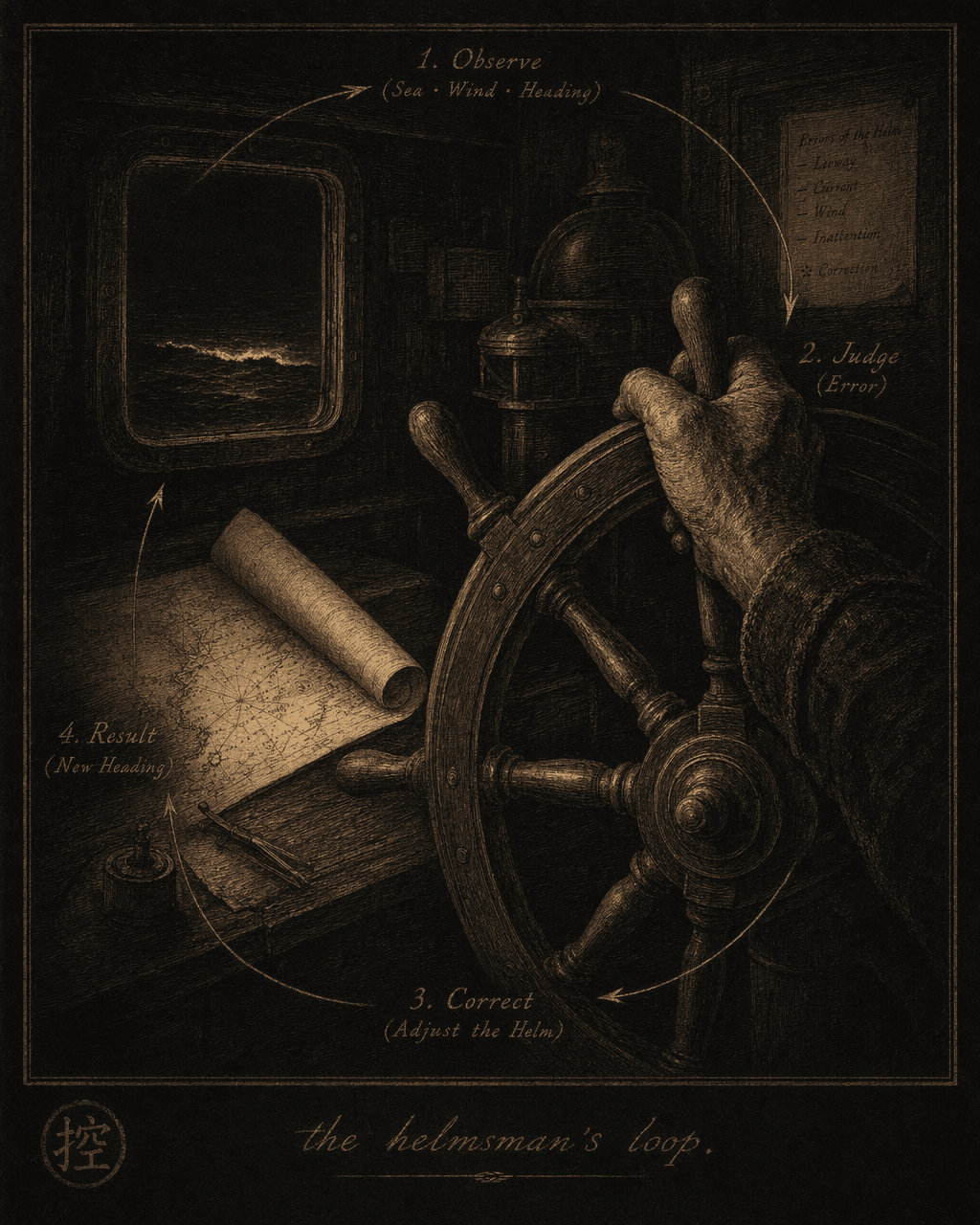
Norbert Wiener used this word to name a discipline: the study of how systems achieve control through feedback — whether the system is a steam engine, a cat, or a social organization.
A system’s function depends on the quality of information flowing through it. Corrupt the information with noise, and the system loses stability. Break the feedback loop, and control becomes an empty word.
— Paraphrased from Cybernetics: Or Control and Communication in the Animal and the Machine (1948)
If you have written any agentic system code, this might sound familiar.
Feedback: an overused word, an underused concept
In everyday language, “feedback” means someone tells you how you did. In cybernetics, feedback is a precise mechanism: the system’s output is routed back as input, shaping the system’s subsequent behavior.
This mechanism has two modes. Note: “positive” and “negative” here do not mean “good” and “bad” — positive feedback is often dangerous, negative feedback is usually what you want. The names are counterintuitive, but the logic is clean:
Negative feedback corrects deviation and drives toward equilibrium. The thermostat is the textbook example — temperature too high, heater off; too low, heater on; the system oscillates around the setpoint. Your agent calls a tool, gets a result, adjusts its next decision accordingly — that is negative feedback at work.
Positive feedback amplifies deviation and drives toward runaway. The screech when a microphone gets too close to a speaker is positive feedback — sound picked up, amplified, picked up again, amplified again, until the system saturates. Your agent produces a hallucination — the model confidently outputs something factually wrong — and that wrong information enters the context. The model, reasoning from a now-corrupted context, produces more errors. Positive feedback — only what runs away is meaning, not sound.
Both modes coexist in every agent system. Negative feedback steers toward the goal. Positive feedback steers away from it — and accelerates.
You are already doing cybernetics
If you have written agent code, you have already been practicing cybernetics.
| What you write in the harness | What cybernetics calls it |
|---|---|
| System prompt, tool definitions | Initial conditions and interface definitions of the control signal |
| Output parser, evaluator | Observer |
| The loop that concatenates tool results and calls the model again | Closed-loop feedback loop |
| Context management (compaction, summarization) | Signal filtering and noise reduction |
| Permission system, sandbox isolation | Constraint boundaries of the actuator |
| Max steps, timeouts | Safety valves against positive-feedback runaway |
These components together form your harness — the entire feedback control system wrapped around the LLM. This system does not require a human in the loop at every turn; harness code closes the loop automatically. The human’s role is at design time, not runtime.
Putting a theoretical framework on these practices is not about padding a resume. It is about seeing something clearly: which of your gut-instinct design choices have theoretical backing, which ones are just getting lucky — and whether theory can help you get lucky more reliably.
The harness is a single whole, but it has internal division of labor. Cybernetics describes that division with three roles — Observer, Controller, Plant.
Further Reading
- Wiener, N. (1948). Cybernetics: Or Control and Communication in the Animal and the Machine. MIT Press.
Observer-Controller-Plant
Knowing the harness is a feedback control system is a start. But “the whole system” is too coarse — when something goes wrong, you have no idea where to look. Cybernetics splits the system into three roles.
Three roles
Plant (the controlled object) — the thing you want to control but cannot directly modify from the inside. In classical control theory, it is a motor, a chemical reactor, the aerodynamic surfaces of an aircraft. In an agentic system, it is the LLM. You give it input; it gives you output. You cannot crack open its parameter matrix and manually tweak a weight — you can only influence its output through its input.
Controller — the part that generates control signals based on observed signals. System prompt, tool definitions, orchestration logic, permission system, context management strategy — these determine “what gets fed to the LLM next turn.”
Observer — the part that senses the plant’s output. Output parser, evaluator LLM (a separate model checking the primary model’s output), human-in-the-loop approval flows, logging systems — they determine “whether the LLM’s output meets the mark, and where the gap is.”
Controller and observer are both your harness code. The plant is the only part that does not belong to the harness — it is what the harness exists to control. OCP is not dividing your system into three separate programs. It is performing responsibility decomposition within the harness: inside the same codebase, which components are doing control, which are doing observation.
Closed loop and open loop
If your agent is just prompt → response, fire and forget, you are doing open-loop control — issuing a command without looking at the result. Open-loop control works when the plant’s behavior is highly predictable.
LLM behavior is not highly predictable — ch-01 covered this: probabilistic output is one of its operational characteristics. So nearly every production-grade agentic system is closed-loop. The ones that are not are either chatbots or rolling the dice.
The essence of closed-loop control is straightforward: observe, compare, adjust, repeat. The agent loop’s while has_tool_calls: execute → feed_back → call_again is this cycle expressed in code.
graph LR
P["Plant<br>(LLM)"] -->|output| O["Observer<br>(parser, evaluator, logs)"]
O -->|error signal| C["Controller<br>(prompt, tools, orchestration)"]
C -->|control signal| P
style P fill:#e8f4fd,stroke:#333
style O fill:#fff3e0,stroke:#333
style C fill:#e8f5e9,stroke:#333Mapping table
Aligning cybernetics terminology with agent system components makes the whole picture click:
| Cybernetics concept | Agent system counterpart | Example |
|---|---|---|
| Plant | LLM | Claude, GPT |
| Controller | Control components in the harness | system prompt, tool definitions, orchestration logic, context management |
| Observer | Observation components in the harness | JSON parser, evaluator LLM, human review, logs |
| Reference signal | Task objective | ”Fix this bug” |
| Error signal | Gap between objective and actual output | Tests still failing |
| Control signal | Next-round input | Adjusted prompt + tool results |
| Feedback | Tool results / evaluation results | bash output, test results, linter output |
You do not need to memorize this table. What you need is an instinct: when you hit a design problem in an agent system, try asking — is this a plant problem, a controller problem, or an observer problem? That single distinction, just sorting into the right bucket, sharpens your troubleshooting direction considerably.
The separation principle
Control theory has a theorem: under conditions of linearity, Gaussian noise, and a few other assumptions, the controller and the observer can be designed independently. You can design the optimal controller first (assuming perfect observation), then design the optimal observer (assuming perfect control), combine them, and the result is still optimal.
LLM systems are neither linear nor Gaussian — the theorem does not apply directly. But the engineering spirit behind it is worth borrowing.
Put plainly: “getting the model to output in the right format” and “checking whether the model’s output is correct” are two different jobs. The first belongs to the controller (prompt engineering, structured output, tool design). The second belongs to the observer (validation, evaluation, testing).
A classic symptom of conflating the two: stuffing a paragraph into the system prompt that says “please verify your own output for correctness” — the controller moonlighting as the observer. Sometimes this works (models do have some self-correction ability), but it couples two problems that could have been optimized independently. Once coupled, every time you adjust the prompt, you cannot tell whether you are tuning control or tuning observation. Debugging becomes guesswork.
Anthropic’s generator/evaluator separation architecture in harness design is exactly this principle in engineering practice — generation and evaluation handled by different components, each iterated independently.
Three roles, one loop, one separation principle — that is the basic skeleton cybernetics gives you. But this skeleton faces a unique challenge: its plant is a language model with a near-infinite output space. How does your controller cope with that kind of variety? Ashby answered this in 1956.
Further Reading
- Ahn, K., Zhang, Z., & Sra, S. (2024). What’s the Magic Word? A Control Theory of LLM Prompting. arXiv:2310.04444
Requisite variety
Observer, Controller, Plant — three roles, one closed loop. The skeleton is in place. But this skeleton faces a challenge unlike anything in classical control: its plant is not a motor with a bounded output space. It is a language model whose output space is practically infinite.
Ashby’s Law
In 1956, W. Ross Ashby proposed a principle that would later be called “the first law of cybernetics”:
Only variety can absorb variety. The number of distinct situations a controller can handle (its variety) must be no less than the number of distinct disturbances it needs to counteract.
The intuition: a thermostat has exactly one control lever — switching the heater on and off. So it can regulate temperature, but not humidity. If you want to control both temperature and humidity, you need a system with at least two independent control levers. The ceiling on control capability is set by the controller’s variety.
Map this to an agentic system: the range of behaviors your harness can handle must cover the range of behaviors the model might produce. Whatever falls outside that coverage is a blind spot — and inside that blind spot, the model’s output goes uncontrolled.
The LLM is a high-variety plant
Classical control theory usually deals with low-variety plants. A motor’s output space is speed and torque. A thermostat’s output is temperature. You can enumerate every possible output state and design a control strategy for each one.
An LLM is nothing like that.
The LLM’s output space is natural language — in theory, the set of all possible token sequences. Even if you cap output at 1,000 tokens, the number of possible combinations is astronomical. You cannot enumerate every possible model output and write a handling branch for each.
Ashby’s Law cuts straight to an engineering directive here: since you cannot make your harness’s variety catch up to an infinite output space, you have to work from the plant side — reduce the variety that needs handling.
Two strategies
Increase the harness’s control capacity
More tools, more complex orchestration logic, more checkpoints, more granular evaluators — expanding the range of model behaviors your harness can recognize and handle.
The cost: the harness itself grows more complex. A complex harness is harder to understand, harder to debug, and more likely to have its own bugs. The controller’s variety has a practical ceiling — it cannot exceed what engineers can comprehend and maintain.
Reduce the plant’s effective variety
Constrain output format. Limit available tools. Narrow task scope. Each of these shrinks the space of behaviors the harness needs to cover — not by restricting what the model can do, but by restricting what you need to handle.
OpenAI distilled a similar lesson while building Codex — “give Codex a map, not a 1,000-page instruction manual.” Use clear architecture docs and constraint rules to bound the agent’s behavior space, rather than sprawling instructions trying to cover every case. This is variety reduction by a different means: not constraining output format through code, but constraining behavior space through documentation.
The two strategies are not either-or. Once you reduce the plant’s effective variety, the residual space the harness needs to cover shrinks — a control problem that was previously impossible becomes tractable. Reduce noise first, then control.
And by the way — “reducing the plant’s effective variety” is itself one of the cumulative investments ch-01 talked about. No matter how capable the model becomes, the work of constraining output format, bounding the tool set, and framing behavior space through documentation does not get replaced by model capability growth. It is orthogonal to model capability.
Why simple harnesses often win
Keep your agent framework simple. The sophistication should be in your tools and in your prompts, not in your agentic framework.
— Anthropic, Building Effective Agents
In Ashby’s terms: do not try to make the harness as complex as the plant. Go the other way — bring the plant’s effective variety down, and a simple harness is enough.
But “simple” is a slippery word. Ashby’s Law has a corollary: the controller is itself a system with its own variety. If the harness’s variety grows too high — past the point where engineers can understand and debug it — it stops being a tool for controlling the LLM and becomes another complex system that needs controlling. The controller spirals out of control while trying to control the plant.
Go too far the other direction, and the harness’s variety drops below what is needed to cover the plant’s residual behavior space. Now you have a system riddled with blind spots.
The meaning of “simple” hides in the math of Ashby’s Law: the harness’s variety matches exactly the variety it needs to handle.
Variety constrained, structure clarified — the next question is: what does this constrained system actually look like at runtime? It is a state machine. But not a typical one.
Further Reading
- Ashby, W. R. (1956). An Introduction to Cybernetics. Chapman & Hall. rossashby.info
- Anthropic. (2024). Building Effective Agents. anthropic.com
An atypical state machine
Variety constrained, harness covering the residual space. What does this constrained system actually look like at runtime?
It is a state machine — formally, it fits the definition perfectly. But it has several unusual properties.
The agent loop is a while loop
At the core of every agentic system sits a loop:
while not done:
output = llm(context)
if output.has_tool_calls:
results = execute(output.tool_calls)
context.append(results)
else:
done = TrueCurrent state (context) + input (tool results) → transition function (LLM inference) → next state (updated context). Formally, that is a state machine.
Tell a computer scientist “the agent loop is a state machine,” and they will nod. But if they try to verify your agent using the methods they use for finite state machines, they will run into trouble.
Classical FSM vs. agent state machine
| Dimension | Classical finite state machine | Agent loop |
|---|---|---|
| State representation | Enumerated type, finite set | Natural language + structured data, combinatorial explosion |
| Transition function | Deterministic, lookup table | Non-deterministic, LLM inference |
| Input alphabet | Finite symbol set | Natural language + tool results, unbounded |
| Transition predictability | Fully predictable | Probabilistic — same input may yield different output |
| Number of states | Finite, enumerable | Effectively infinite |
| Termination condition | Reaching an accept state | Model decides to stop (or harness forces a stop) |
| Transition trigger | Synchronous — input arrives, transition fires | Mix of synchronous and asynchronous events |
Three atypical properties
A classical FSM’s states look like enum { IDLE, WORKING, DONE } — finite, discrete, exactly comparable. The agent loop’s “state” is the entire content of the context window — potentially tens of thousands of tokens of natural language.
“Are two states identical?” is itself a fuzzy question. An extra sentence in the context, a missing sentence, a rephrasing — same state or different state? There is no precise answer. Context management (compaction, summarization) is, at its core, state dimensionality reduction — compressing an infinite state space into a subspace where approximate comparison becomes possible.
A classical FSM’s transition function is deterministic: state A + input X → always state B. The agent loop’s transition function is LLM inference — feed the same context and same tool results in twice, and you may get different next-step decisions.
This is not a bug in the implementation. It is a property of the mechanism — ch-01 covered this: probabilistic output is one of the LLM’s operational characteristics.
A classical FSM halts when it reaches a predefined accept state. The agent loop halts when the model “believes the task is done” — and that judgment is itself probabilistic. The model may declare completion before the task is actually finished (false positive), or keep performing meaningless operations after the task is already done (false negative).
Every production-grade harness has external termination mechanisms — max steps, timeouts, human interrupts. Not because the model cannot be trusted, but because probabilistic judgment needs a backstop.
Beyond the while loop: event-driven execution
The synchronous loop described above is the agent loop’s main path. But a production harness does not run just one while loop — it is an event loop.
Off the main path, asynchronous signals arrive continuously:
- Hooks: pre-tool-call and post-tool-call hooks fire at specific nodes on the main path, able to intercept, modify, or abort execution.
- External interrupts: user cancellation, timeout signals, CI status changes — events that can break into the main path at any moment.
- Event-driven kickoff: the agent’s startup itself is not necessarily triggered by a human hand. State changes in the outside world (data arriving, upstream service pushes, scheduled triggers, output from another agent) can all serve as trigger conditions for agent execution. In production orchestration layers, event-driven agent kickoff is a common pattern — the state machine’s very first transition is already asynchronous.
Classical FSMs do not face this dimension — their transitions are synchronous, one input per transition. The agent state machine’s transitions are both synchronous (LLM output → tool execution → result injection) and asynchronous (external events injected at any time). This makes the harness’s runtime model closer to an event-driven reactor than a simple while loop.
Facing this atypical state machine, the industry has developed two constraint strategies:
Explicit graph (LangGraph): overlay a deterministic graph structure on top of the non-deterministic LLM transitions — you define which nodes can transition to which; the LLM calls inside each node remain probabilistic. Deterministic skeleton + probabilistic muscle.
Implicit loop (Claude Agent SDK / OpenAI Codex harness): no predefined explicit graph. Instead, tool definitions + hooks + permission systems constrain the agent’s available action space at each step. The loop itself is general-purpose; constraints are injected through runtime configuration.
Neither is right or wrong — they serve different scenarios. When the workflow can be predefined, the explicit graph is more transparent. When the workflow demands flexible exploration, the implicit loop is more natural.
Near-infinite state space, non-deterministic transition function, probabilistic termination, a mix of synchronous and asynchronous drivers. This is still a state machine — you just cannot verify it with classical methods.
With the runtime shape understood, one dimension remains unexplored: the feedback loops on this state machine are not single-layered.
Further Reading
- LangGraph Documentation. langchain-ai.github.io
Feedback layers
Feedback is the mechanism that routes a system’s output back as input — negative feedback corrects deviation, positive feedback amplifies it. But feedback does not happen in just one place. Pull the camera back from a single tool call to the full lifecycle of an AI system, and at least four nested feedback loops come into view.
Four layers
| Layer | Timescale | Feedback signal | Trigger | Corrects |
|---|---|---|---|---|
| Token | Milliseconds | Preceding tokens → next-token probability | Autoregressive; fires every step | Token distribution randomness |
| Turn | Seconds to minutes | Tool result → next-round prompt | Event-driven; fires on tool-call completion | Single-step decision deviation |
| Session | Minutes to hours | Task outcome evaluation → strategy adjustment | Mixed timing + events (CI results, user interrupt) | Cross-turn accumulated drift |
| Alignment | Weeks to months | Human preferences → model weight update | Training cycle | Systematic bias in model weights |
The model’s autoregressive mechanism: every token it generates becomes part of the input for the next token. This loop closes on a millisecond timescale. You cannot intervene here directly — unless you are doing inference-time intervention research. It is feedback internal to the plant, outside the harness’s control surface.
The core feedback of the agent loop. Model calls a tool → tool returns a result → result gets spliced back into context → model makes the next decision. This is the harness engineer’s primary operating theater. Your system prompt, tool definitions, output parsing — they all live at this layer. Each closure of the Observer-Controller-Plant loop is one turn-level feedback cycle — and one step through the atypical state machine.
The execution cycle of a complete task. The evaluation that follows — did tests pass? is the user satisfied? — may trigger strategy adjustments: a different prompt template, a different tool combination, a revised context-management approach. Human-in-the-loop intervention mainly happens here.
As harnesses mature, session-level feedback is shifting from manual to automated. In Anthropic’s long-running agent architecture, the handoff between initializer agent and coding agent, the automatic updates to feature tracking — these are automated session-level feedback. No human standing at every session boundary pressing buttons.
Human preference signals get aggregated and, through training, alter the model’s weights. Unless you are a model provider, this is not your direct control surface — but it determines the baseline behavior of your plant. Ch-01 noted that capability grows predictably with scale; alignment-level feedback is one of the mechanisms that shapes the direction of that growth curve.
Nested loops
Each layer is a complete Observer-Controller-Plant circuit. Inner layers run fast, outer layers run slow — but the outer layer sets the boundary conditions under which the inner layer operates.
Training changes the model’s weights, so every token-level probability distribution shifts. You revise the system prompt, so every turn-level model behavior shifts. The slow layer determines what the fast layer can and cannot do.
Harness engineers mainly operate at the turn and session levels. But knowing which layer your control signal actually takes effect in — and which behaviors are not yours to change at your layer — that boundary awareness matters.
The danger of positive feedback
At the turn level, hallucination is a textbook positive-feedback process: the model generates incorrect information → incorrect information enters the context → the model generates based on the corrupted context → errors accumulate and amplify. Each turn-level feedback cycle does not correct the deviation — it widens it.
One of the core responsibilities of harness engineering: intervene before positive feedback runs away. Observers that validate tool results, controllers that run sanity checks, termination mechanisms that cap autonomous execution steps — all of them are negative-feedback devices, counteracting the turn-level tendency toward positive feedback. The microphone-squeal analogy from 01 gets a more concrete anatomy here.
This also gives another angle on the separation principle from 02: why the evaluator needs to be independent from the generator. If the generator is responsible for checking its own output (controller doubling as observer), positive feedback can quietly accumulate in the generator’s blind spots — it cannot see its own errors, so it cannot correct them. An independent evaluator provides negative feedback from outside, breaking the loop.
Up to this point, the perspective has been from outside the system. But one question has gone unasked: when you are tuning a prompt, are you part of the system?
Further Reading
- Christiano, P. et al. (2017). Deep Reinforcement Learning from Human Preferences. arXiv:1706.03741
Second-order cybernetics
What are you doing when you tune a prompt?
Observing the model’s output, judging how far it lands from where you want it, modifying the system prompt, observing the new output. The cycle might run for hours. You are a controller operating at the session-level timescale.
But you are also part of the system. Your design decisions shape the system’s behavior, and the system’s behavior shapes your next design decision. You are inside.


In 1974, Heinz von Foerster drew a line through this phenomenon.
First order and second order
First-order cybernetics
The cybernetics of the observed system. You stand outside, studying how it works. Plant over there, observer over here, clean boundary. The first five articles — from OCP structure to feedback layers — all took this vantage point.
Second-order cybernetics
The cybernetics of the observing system. You recognize that the observer is inside the system, and that the act of observing changes the system being observed. Not “I am watching how it runs,” but “I am watching how it runs, and my watching changes how it runs next.”
The first-order view handles most engineering problems. But some phenomena only come into focus through the second-order lens.
You are the adaptive controller
The iterative process of tuning a prompt has a name in control theory: adaptive control — a controller that adjusts its own strategy in real time based on the behavior of the controlled system.
In classical adaptive control, the controller is an algorithm. In the development of an agentic system, the controller is you — a human engineer, observing behavior, judging outcomes, and adjusting strategy on a session-level timescale. The process of designing the harness is itself a feedback loop, just one that closes far more slowly than the turn level.
Second-order cybernetics describes exactly this structure: no one-way arrow between observer and observed system, only a loop.
When the system observes itself
More interesting than you tuning a prompt: the model can do something similar on its own.
An agent generates, checks its own work, corrects itself — generator and evaluator are the same model.
Constitutional AI pushes this logic into the training layer: the model critiques its own output using a set of principles, generates preference data from its own judgments, and uses that data to train its own reward model. Observer and observed collapse into one.
Papers, code, quantifiable results all exist — but the approach rests on one premise: the system’s self-assessment is reliable enough.
Self-correction depends on a premise: the model’s judgment in the target domain is strong enough to evaluate its own output. If it is not, self-correction can turn correct output into incorrect output — a bad self-assessment is more dangerous than no self-assessment at all.
Anthropic’s circuit-tracing research has found that models sometimes exhibit introspective awareness — they can report what they are doing, and the reports sometimes align with internal computation paths. Whether this constitutes some form of “self-awareness” is a question serious researchers are still debating. For engineering, what matters is not the philosophical verdict but an operational question: on your specific task, is the model’s self-assessment accurate?
Separation principle meets second-order view
02 said the responsibilities of controller and observer should be separated. This article says observer and observed can collapse into one. No contradiction — they speak at different layers.
The separation principle is an engineering guideline internal to the harness: within the same codebase, control components and observation components each do their own job, optimized independently. A first-order view.
The second-order view concerns something else. No matter how you design the harness, you (as the designer) and the system always form a loop — your design affects behavior, behavior affects your next design. This loop cannot be eliminated, only recognized. And recognizing it is understanding why “getting the harness design right” is not a task with an endpoint but an ongoing iterative process.
The perspectives that cybernetics can offer agentic-system engineering are mostly laid out now. One question remains: all these perspectives together — where exactly is the line they draw?
Further Reading
- Von Foerster, H. (1974). Cybernetics of Cybernetics. University of Illinois.
- Bai, Y. et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073
- Anthropic. (2025). Circuit Tracing: Revealing Computational Graphs in Language Models. transformer-circuits.pub
The boundary with traditional software
The question left open by 06: where is the line?
Three dividing lines
Traditional software: f(x) = y holds every time. Same input, same output. Tests can assert exact values.
Agentic systems: f(x) may differ each run. Ch-01 established that probabilistic behavior is an operational characteristic of LLMs. You cannot verify an agent’s behavior with assertEqual — you need statistical methods.
Traditional software uses APIs, type systems, and compilers for enforcement. Wrong parameter type? The build fails.
Agentic systems use natural language as their control signal — the prompt. “The prompt is ambiguous” and “the API parameter type is wrong” are errors from two different universes. The first has no compiler to catch it.
A traditional system’s behavior = the union of all code paths, theoretically enumerable.
An agentic system’s behavior set cannot be enumerated — the model may do anything within its capability range. The requisite-variety problem discussed in 03 has its root here.
Different plant, different engineering
The three lines converge: traditional software’s plant is deterministic, low-variety, and driven by typed interfaces. An agentic system’s plant is non-deterministic, high-variety, and driven by natural language.
Different plant, different harness design principles.
| Dimension | Traditional software | Agentic system | Cybernetics concept |
|---|---|---|---|
| Verification | Unit tests, integration tests (deterministic assertions) | Statistical validation, adversarial testing | 04 non-deterministic transitions |
| Observability | Logs, metrics, traces | + reasoning-path tracing, context auditing | 02 observer variety |
| Safety | Input validation, access control | + sandbox isolation, least-privilege tools, output auditing | 03 constraining plant variety |
| Debugging | Breakpoints, stack traces | + prompt replay, context snapshots | 04 natural-language state |
| Iteration | Change code, run tests | + tune prompts, watch for behavior drift | 06 second-order feedback |
You would not debug a jet engine the way you debug a compiler. They are different systems with different failure modes.
What stays, what changes
The core of engineering discipline does not move: rigor, repeatability, verifiability.
What changes is the concrete form that discipline takes. What does “repeatable” mean when execution is non-deterministic — exact reproduction, or statistical stability? What counts as “verified” — asserting an exact value, or checking a distribution? And “observable” — tracing code paths, or tracing reasoning paths?
Orthogonality was about where to point your force. Cybernetics is about the mechanism — a multi-layered feedback control system running on an atypical state machine, with you as part of it.
The mechanism is clear. Next question: what happens to this system over long runs?
Further Reading
- Schneier, B. & Raghavan, B. (2025). On the OODA Loop and Agentic AI. schneier.com