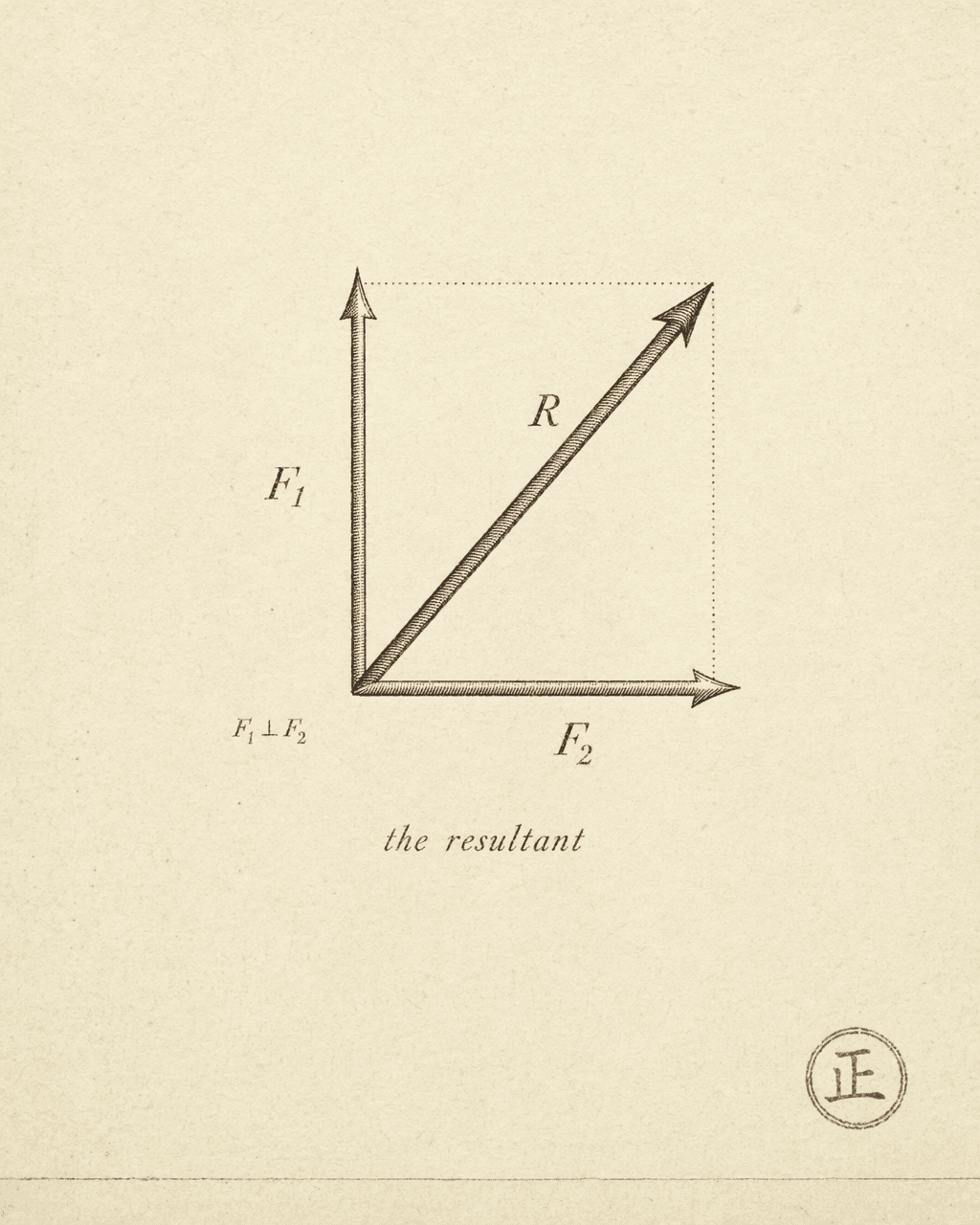
Orthogonality
The resultant
You learned this in high school physics: an object’s motion is never determined by a single force. It is the resultant of every force acting on it.
How fast a car goes is not just about the engine. Road friction, air resistance, tire grip, transmission efficiency — they all shape the outcome. A powerful engine on bald tires is just noise and heat.
Agentic systems work the same way.
When you plug an LLM into tools, feed it context, wrap it in a runtime framework, and deploy it inside a sandbox, the system’s final performance — how complex a problem it solves, how reliably it finishes a task, how autonomously it operates — is the resultant of all these forces, not the solo act of any one.
Model capability is one force. It sets the ceiling on the system’s intelligence — reasoning depth, knowledge breadth, instruction-following precision.
Everything you do at the harness layer — how you arrange context, design tool interfaces, manage runtime state, isolate execution environments, validate outputs — is another force. It determines how much of that ceiling gets realized in practice, and whether the process is safe, controllable, and sustainable.
Two forces, acting on the same system. The resultant determines what comes out.
This leads to a question — a simple-sounding one that will reshape your entire engineering strategy:
Where should your force point?
Point it wrong, and every ounce of effort you invest gets quietly eaten by the other force’s growth. Point it right, and the two forces do independent work — neither diminishes the other, and the system keeps getting stronger.
“Pointing it right” has a precise name in physics. But before we get to that word, we need to understand the force we cannot control — the model itself — and what it actually is.
The first force: what is the model
To decide where your force should point, you need to see what the other force looks like.
A completer that has read everything
Strip a modern large language model down to its core, and it is doing one thing: predicting the next token.
You give it a sequence of text — a question, some code, half an article — and it returns a probability distribution: “Given everything I have seen in human text, which token is most likely to follow this sequence?” It appends that token, then predicts the next one. Over and over, until it decides to stop.
That is it. Nothing more.
If you were expecting a digital oracle pondering in silicon, this might be disappointing. But hold off on the disappointment — the interesting part comes right after “that is it.”
A simple objective, complex emergence
Next-token prediction is a plain, almost boring objective function. But put it in a large enough parameter space and train on nearly all of the text humans have produced, and unexpected things begin to happen.
The model starts writing code, solving math problems, analyzing complex business cases. It follows multi-step instructions, performs operations that look like reasoning, and generates text that human readers find insightful.
None of this was directly programmed in. The training objective was always the same — get the next token right. But in pursuing that objective, the model developed internal structures that the objective never explicitly asked for.
Mechanistic interpretability — a research field dedicated to reverse-engineering neural network internals — has started confirming this with experimental data. MIT Technology Review listed it among the 10 Breakthrough Technologies of 2026.
- Othello-GPT: A model trained only on Othello game transcripts (character sequences of moves) spontaneously developed structured internal representations of the board state. It was not just predicting the next move symbol — in some meaningful sense, it “knew” what the board looked like.
- Space and time representations: Gurnee and Tegmark found that LLM internal representations encode geographic spatial relationships between cities and temporal ordering of events. These structures were not required by the training objective, yet they exist in the model’s parameters.
In 2025, Anthropic’s circuit tracing research tracked computation paths inside Claude from input to output. A few findings are worth noting:
When asked for “the opposite of small,” whether in English, French, or Chinese, the model activates the same set of concept features internally — first “smallness” and “opposition,” then “largeness,” then translates into the language of the question. It is not doing three separate translations. It has a cross-lingual semantic space.
When writing poetry, the model picks candidate rhyming words first, then works backwards to compose the preceding line. Not word-by-word guessing — planning the destination before paving the road.
When answering “What is the capital of the state Dallas is in?”, the model first activates “Dallas → Texas,” then jumps to “Texas capital → Austin.” It is composing independent knowledge fragments, not recalling a pre-stored answer.
In June of the same year, another study showed that LLMs encode linear spatial world models internally — not just game board states, but general physical space representations.
Does it “understand”?
Here we reach a fork in the road. On one side, Bender et al.’s “stochastic parrots” argument — language models are doing sophisticated statistical collage, and co-occurrence is not comprehension. On the other side, the empirical findings above suggest that under next-token prediction pressure, models develop internal encodings of world structure — something that at least resembles the beginnings of understanding.
The debate continues. Both sides have serious researchers and arguments that cannot be dismissed. There will be no resolution soon.
But as engineers, we do not need to wait for the referee’s whistle.
Whatever you call these emergent behaviors — “understanding,” “statistical emergence,” or something else — the model’s operating mechanism is known: it does next-token prediction, and its behavior is shaped by training data and parameter space. Your engineering decisions should be based on this mechanism’s operational characteristics, not on whether there is a soul behind it that truly “gets it.”
Operational characteristics
Four characteristics that matter for engineers:
| Characteristic | What it means |
|---|---|
| Probabilistic | Same input does not guarantee same output. You get a sample drawn from a probability distribution, not the return value of a deterministic function. |
| Stateless per inference | Every call is a fresh computation. When it “remembers” something from the previous turn, that is because you (or your harness) fed the prior context back in. |
| Context window bound | There is a hard ceiling on how much information it can “see.” Anything beyond that window does not exist, as far as the model is concerned. |
| Capability scales predictably with compute | More parameters, more data, more compute → lower prediction error → stronger emergent behaviors. Not faith — an empirical regularity verified over and over. |
These four constraints are what you actually need to care about when working with the model. It is strong, and getting stronger — but how it gets stronger has structure.
So: how strong is it? How fast is it getting stronger?
Further Reading
- Anthropic. (2025). Tracing the Thoughts of a Large Language Model. anthropic.com
- Anthropic. (2025). Circuit Tracing: Revealing Computational Graphs in Language Models. transformer-circuits.pub
- Anthropic. (2025). On the Biology of a Large Language Model. transformer-circuits.pub
- Anthropic. (2025). Emergent Introspective Awareness in Large Language Models. transformer-circuits.pub
- Tehenan, M., Bolivar Moya, C., Long, T., & Lin, G. (2025). Linear Spatial World Models Emerge in Large Language Models. arXiv:2506.02996
- Li, K., Hopkins, A. K., Bau, D., Viégas, F., Pfister, H., & Wattenberg, M. (2023). Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. arXiv:2210.13382
- Gurnee, W. & Tegmark, M. (2023). Language Models Represent Space and Time. arXiv:2310.02207
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? doi:10.1145/3442188.3445922
- MIT Technology Review. (2026). Mechanistic Interpretability: 10 Breakthrough Technologies 2026. technologyreview.com
How strong is this force, and is it still growing
The mechanism is clear now, but knowing “it does next-token prediction” is not enough. You need a feel for the magnitude of this force, and how fast it is increasing.
Not a line — concentric rings
If you only look at benchmark score charts, model capability growth looks like a steep line going up. But that line hides a more interesting structure: capability is not just climbing on one dimension. It keeps unlocking new dimensions.
Think of it as concentric rings expanding outward — each new capability layer stacks on top of all previous ones. Earlier rings do not disappear; they become the foundation for the next.
| Period | Capability dimension unlocked | Landmarks |
|---|---|---|
| 2020–2022 | Text fluency and knowledge | GPT-3 showed that scale alone produces emergent capabilities; PaLM confirmed it |
| 2022–2023 | Instruction following and alignment | ChatGPT used RLHF (reinforcement learning from human feedback) to make models usable; Claude 1 was designed around safety alignment |
| 2023 | Reasoning + multimodal (unlocked in parallel) | GPT-4 brought a reasoning leap and vision input at the same time; Gemini 1.0 was natively multimodal; Claude 2 pushed context to 200K |
| 2023–2024 | Tool use and structured output | Function calling, Claude tool use, JSON mode — note that this came before extended reasoning |
| 2024–2025 | Test-time compute / deep thinking | o1 introduced the “thinking tokens” paradigm; DeepSeek-R1 proved open source could do it too; Claude extended thinking lets the model “think before answering” |
| 2025–2026 | Model’s agentic capabilities | Claude Code supports agent teams working in parallel; OpenAI Codex runs autonomously in cloud sandboxes; Claude Opus 4.6 leads GPT-5.2 by ~144 Elo on GDPval-AA (economic knowledge work evaluation) |
Each row does not replace the row above it — it stacks on top. A 2026 model is not just “more agentic.” It is simultaneously more fluent, more aligned, better at reasoning, more multimodal, better at tool use, and better at deep thinking. All six dimensions are growing at once; each period just happens to be the one where a new dimension gets unlocked.
Three years, one product line
Let us make this growth concrete with a single product line.
March 2023: Claude 1
Context window: 9K tokens — roughly enough for one medium-length article. Capabilities: conversational, could write text, some reasoning ability but nothing you would call reliable. No vision, no tool use, no deep thinking.
February 2026: Claude Opus 4.6
Context window: 1M tokens — 111 times Claude 1. Output ceiling: 128K tokens. Supports adaptive thinking (the model decides on its own when deep reasoning is needed). In agent teams mode, multiple agent instances collaborate in parallel on complex tasks. Top score on Terminal-Bench 2.0 for agentic coding. Industry-leading on knowledge work evaluations in finance and law.
Three years. Same company, same product line. From “can chat” to “can assemble a team and autonomously complete complex software engineering tasks.”
Cautious optimism
The force is still growing — current evidence supports this. But the sources of growth are diversifying:
- Pre-training scale continues to advance, but has hit a bottleneck in high-quality data. The industry response: synthetic data, aggressive data curation, and multi-epoch training.
- Test-time compute has become a new scaling axis. Letting the model “think longer” sometimes matches the effect of a 10–100x increase in model size — and this path has a long way to go.
- The model’s own agentic capabilities keep improving — better planning, longer autonomous execution, more reliable self-correction.
The direction is roughly visible — deeper reasoning, longer context, more modalities, more reliable autonomous execution. But the timeline is anyone’s guess.
Anthropic, in a blog post about how to build well with Claude, wrote:
“The frontier of Claude’s intelligence is always changing. Assumptions about what Claude can’t do need to be re-tested with each step change.”
Remember that line. We will translate it into the language of mechanics shortly.
This force is not just getting stronger — might its direction also be changing?
Further Reading
- Kaplan, J., McCandlish, S., Henighan, T., et al. (2020). Scaling Laws for Neural Language Models. arXiv:2001.08361
- Hoffmann, J., Borgeaud, S., Mensch, A., et al. (2022). Training Compute-Optimal Large Language Models. arXiv:2203.15556
- Anthropic. (2026). Introducing Claude Opus 4.6. anthropic.com
- OpenAI. (2025). Introducing Codex. openai.com
- Anthropic. (2026). Models Overview. platform.claude.com
Is the force changing direction
Knowing the model is getting stronger is not enough. If the force were just growing along the same direction, you could pick a fixed orthogonal direction and get to work.
But what if it is getting stronger and turning at the same time? That is a different engineering problem.
The current mainstream: Transformer
The dominant architecture today — the Transformer — is built on one core mechanism: self-attention. Every token can “see” every other token in the context, and computes its representation accordingly. This is where your context window comes from: how much the model can see depends on how long a sequence the attention mechanism can cover.
An LLM built on the Transformer architecture is, at bottom, a statistical model over text sequences. Through next-token prediction it has learned the structure, knowledge, and reasoning patterns of human language. It is powerful — but “understanding the world by predicting text” is only one way to encode the world.
At least three other paths are evolving.
Four ways to encode the world
| Transformer | State space model (SSM) | Energy-based model (EBM) | World model | |
|---|---|---|---|---|
| In one line | A completer that has read all text | A stream processor with finite memory | A judge scoring global compatibility | An imaginer that simulates physical consequences |
| Modeling objective | Given prior context, which next token is most likely | How to compress all history into a fixed-size state vector | How plausible is this entire configuration | If I take this action, what does the world become |
| How it “understands” the world | Extracts statistical regularities from text co-occurrence | Models sequence dynamics as state evolution | Searches for low-energy states in a global configuration landscape | Learns causal structure and state transitions |
Represented by the Mamba family. Inspired by dynamical systems from control theory: a fixed-size hidden state evolves over time, and each new input determines how the state updates — what to keep, what to forget.
The difference from Transformers is fundamental. Transformers store all past tokens in a structure called the KV cache (think of it as “conversation memory”) and let every token randomly access any prior information. SSMs compress the full history into a fixed-size state vector — constant memory, but lossy. Faster and more memory-efficient on very long sequences, but weaker at precise retrieval.
The Mamba-3 authors (2025) themselves acknowledged: “linear layers will predominantly be used in conjunction with global self-attention layers.” The industry consensus is converging on hybrid architectures — for example, AI21’s Jamba: 7 Mamba layers per 1 attention layer, 256K context on only 4GB of KV cache, 3x the throughput of comparable Transformers.
Represented by Yann LeCun’s JEPA architecture. A completely different approach: instead of sequential prediction, define an energy function that scores entire input configurations — low energy means “compatible, plausible,” high energy means “contradictory, unnatural.”
Inference is not “sample one token at a time” but “find low-energy states in the energy landscape” — fundamentally an optimization process, not a sampling process. JEPA variants operate in embedding space: they predict learned abstract representations rather than raw pixels or text, forcing the model to discard irrelevant detail and focus on structure.
LeCun left Meta in late 2025 to found AMI Labs, which raised 3.5B valuation in March 2026 — specifically to pursue energy-based world models.
These aim to close the gap between describing causality and modeling causality. When an LLM says “gravity makes objects fall,” it is because the training text contained that sentence and variations of it — what the model learned is a linguistic description of causality. A world model’s goal is to learn the actual dynamics of physics: objects persist, gravity pulls down, collisions transfer momentum, actions have consequences.
DeepMind’s Genie 3 generates interactive 3D worlds through frame-by-frame prediction, and emergent intuitive physics (gravity, collisions, object permanence) appears within them. NVIDIA’s Cosmos platform trains physical AI on over 20 million hours of real-world data. Short-horizon physical simulation works today — but long-horizon general planning and reasoning remains an open frontier.
Not mutually exclusive
You might assume these are four diverging paths, and someday one will win. The actual picture is more interesting.
A late-2025 paper proved that autoregressive models and energy-based models have a bijection in function space — connected through the soft Bellman equation from maximum-entropy reinforcement learning. Every autoregressive model implicitly defines an energy function, and vice versa. This is a mathematical equivalence, not an engineering one — training methods, inference costs, and practical applications still differ widely. But it shows these paths share deeper theoretical roots than they appear to.
SSMs are converging with Transformers in practice, not replacing them. Current world model implementations are largely built on top of Transformer architectures. These paths are merging, not forking.
What this means for harness engineering
But they do represent different directions for the force.
- If future models can natively simulate causal relationships (world models), the chain-of-thought scaffolding you build at the harness layer — where you are essentially doing the model’s planning for it — may become unnecessary.
- If future models can operate over lossless infinite context (the SSM limit case), the context window management strategies you carefully designed — compression, summarization, forgetting, retrieval — may become unnecessary.
- If future models can globally evaluate the plausibility of an entire configuration (EBM), the step-by-step reasoning pipelines you built to make the model “think through” problems may become unnecessary.
These are “may,” not “will.” These architectures are still early — LeCun’s AMI Labs just closed its round; pure SSMs still underperform Transformers on retrieval-heavy tasks; long-horizon reasoning and planning in world models remains a research frontier, not engineering reality.
But the trend is visible: models are trying to encode the world at a more fundamental level than next-token prediction.
This force is not just growing stronger. It may be turning.
Further Reading
- Hounie, I., Dieng, A. B., & Dathathri, S. (2025). Autoregressive Language Models Are Secretly Energy-Based Models. arXiv:2512.15605
- Gu, A. & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv:2312.00752
- Cartesia. (2025). Mamba-3: An Inference-First State Space Model. blog.cartesia.ai
- AI21 Labs. (2024). Jamba: AI21’s Groundbreaking SSM-Transformer Model. ai21.com
- Meta AI. (2023). I-JEPA: The First AI Model Based on Yann LeCun’s Vision for More Human-Like AI. ai.meta.com
- NVIDIA Research. (2025). Energy-Based Diffusion Language Models for Text Generation. research.nvidia.com
- LeCun, Y. / AMI Labs. (2026). AMI Labs raises 3.5B valuation to build energy-based world models. source
- Introl. (2026). World Models Race 2026: LeCun, DeepMind, and Beyond. introl.com
Orthogonal decomposition: where should your force point
The force’s direction is visible, and it may be turning. Back to the question the first piece left open:
Where should your force point?
Aligned forces
Picture two forces acting on the same object, pointing in the same direction. The resultant is large. But when one force keeps growing, the marginal contribution of the other shrinks.
If the engine already delivers 500 horsepower, strapping a small fan to the roof to blow forward does technically increase the resultant. But the fan barely matters. Worse, when the engine upgrades to 1,000 horsepower, the fan is not just useless — its weight becomes drag.
Map this to agentic systems: if what you do at the harness layer points in the same direction as model capability growth — compensating for a capability dimension the model currently lacks — then every time the model gets stronger along that dimension, your work erodes a little.
Remember the Anthropic line?
“Assumptions about what Claude can’t do need to be re-tested with each step change.”
Translated into mechanics: the shelf life of a force aligned with model capability depends on the interval between model upgrades.
This does not mean the work has no value — right now, with models not yet strong enough, it is necessary. But you should be clear-eyed about what it is: a depreciating investment, not a compounding one. Its value decays as the model gets stronger.
Orthogonal forces
Now picture two forces at 90 degrees to each other.
In this configuration, each force does independent work along its own axis. Neither interferes with the other. No matter how strong one force becomes, the other’s contribution is completely unaffected. The resultant is not a simple sum but a vector sum — the system gains an additional degree of freedom.
Map this to agentic systems: there are things you can build whose value does not depend on how strong the model is today or how strong it will be tomorrow. Whether reasoning capability increases tenfold, whether context windows expand to infinity, whether the architecture shifts from Transformer to energy-based models or world models — these things still have independent value.
They are orthogonal to model capability.
A criterion, not an answer
I am not going to list “which things are orthogonal.” The reason is simple: if I did, it would be another list with an expiration date.
What I will give you is a criterion:
For any harness engineering decision you are making or about to make, ask yourself one question —
If the model suddenly became ten times stronger on this dimension tomorrow, would what I am doing today become more valuable, or unnecessary?
- If the answer is “unnecessary” — your force is aligned with the model’s force. You are making a depreciating investment. Not wrong to do, but know its shelf life.
- If the answer is “unaffected, or even more valuable” — your force is orthogonal to the model’s force. This is a compounding investment. Every unit of effort adds a degree of freedom that the model cannot provide on its own.
- If the answer is “I am not sure” — that is a useful discovery too. Go back to the previous article and look at the model capability evolution vector. Think about the projection of your work onto that vector. Large projection, be cautious. Projection near zero, you are in good shape.
Do not fight a force you cannot control. Find the direction perpendicular to it, and do what it cannot.
Further Reading
- Anthropic. (2026). Harnessing Claude’s Intelligence. claude.com/blog