Causality
Hume’s Fork
For roughly two thousand years, “cause” needed no explanation.
Aristotle organized causation into four neat categories — material, formal, efficient, and final. A statue’s material cause is its marble, its formal cause is its shape, its efficient cause is the sculptor’s chisel, its final cause is the commemorative purpose it serves. The Four Causes framework assumed something deep: that causal relationships are part of the objective fabric of reality, and that human reason can access, classify, and fully grasp them.
This assumption went largely unchallenged for centuries. Then a Scottish philosopher sat down at a billiard table.
The revolution on the billiard table
Hume asks you to run a thought experiment.
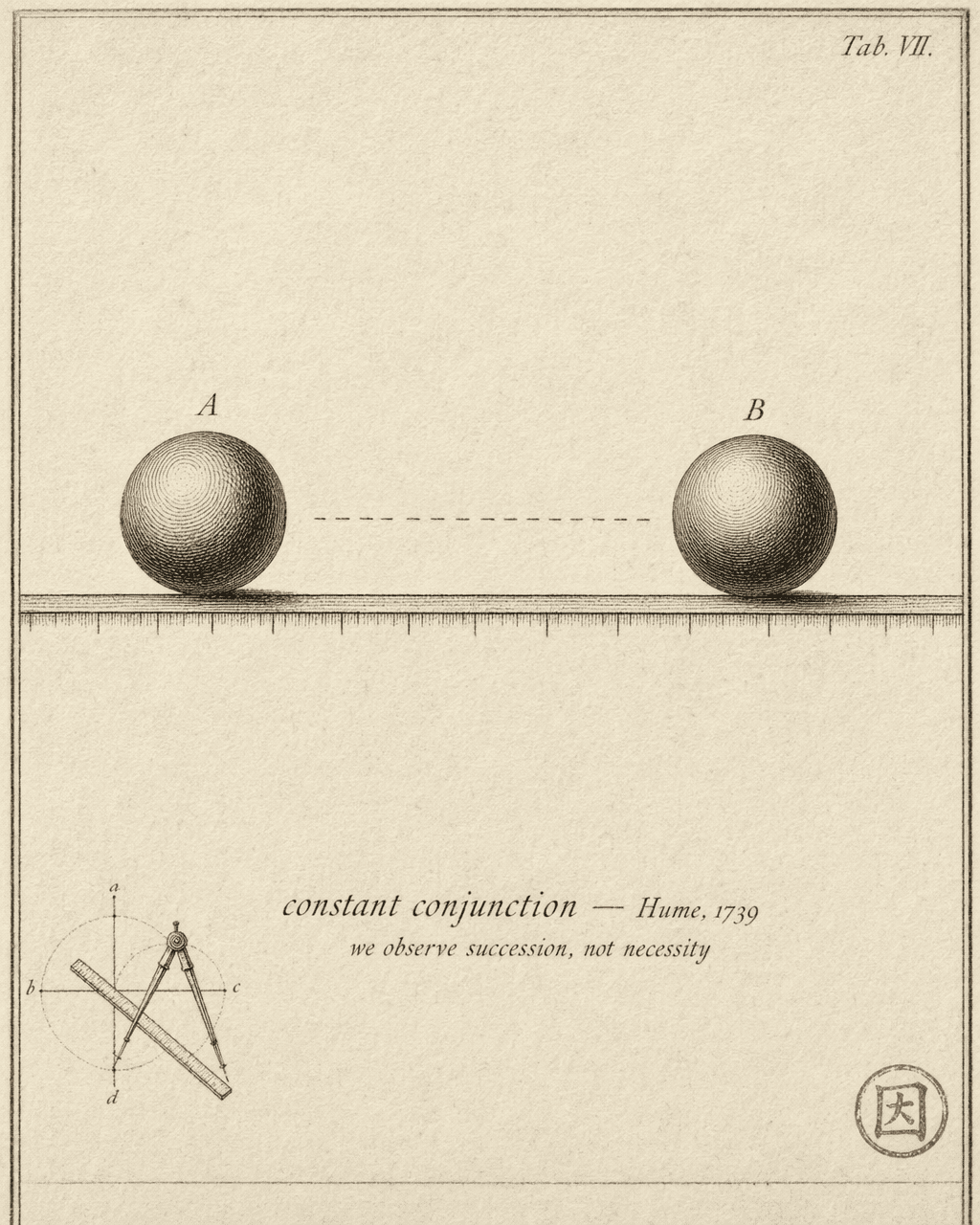
Picture yourself watching one billiard ball strike another for the very first time. Ball A rolls forward, makes contact, and Ball B moves.
Now erase everything you’ve ever known about billiards. From this single observation alone, can you infer that “the collision caused the motion”?
Hume’s answer: no.
You witnessed two events in succession — Ball A moved, contact occurred, Ball B moved. But what did you observe between those events? Nothing. No force visibly flowing from A to B. No “causation” hanging in the air. You saw: A moved first, B moved second. Full stop.
What if you watch it a hundred times? A thousand?
Each repetition increases your confidence that “when A hits B, B moves.” But what accumulates is not observation of some hidden mechanism — it’s statistical confidence in a pattern. What you observe is still constant conjunction: events of this type reliably follow events of that type.
You never observe “causation” itself.
Three paths, all blocked
Hume didn’t just assert this. He systematically eliminated every possible rational foundation for causal inference.
A priori reasoning? No good. Effects are distinct events from their causes. No amount of inspecting the idea of a cause can tell you what its effect will be. A person who has never seen fire cannot — through pure reason alone — deduce that it burns. Adam, even endowed with perfect rational faculties, could not know before his first encounter with water that it could drown him. The idea of the cause does not contain the idea of the effect.
Empirical reasoning? Circular. You might try to argue that past experience justifies expecting the future to resemble the past. But this argument requires a premise: that nature is uniform — that what has happened will continue to happen. Philosophers call this the Uniformity Principle.
The trouble: how do you prove the Uniformity Principle?
By deduction? No — “the future will differ from the past” involves no logical contradiction. The sun not rising tomorrow is entirely conceivable. By induction? Also no — “past experience shows that the future always resembles the past” is itself an appeal to the Uniformity Principle. You’re using the very thing you’re trying to prove.
A genuine vicious circle.
Direct observation of necessity? Impossible. We never observe any “connection” between two events. The billiard collision: you see motion A, contact, motion B. Where in that sequence did you see necessity? Your will moves your arm: you decide to raise your hand, and it rises. But do you have any insight into the mechanism linking intention to movement? None. You experience intention followed by movement — once again, temporal succession and nothing more.
When we look about us towards external objects, and consider the operation of causes, we are never able, in a single instance, to discover any power or necessary connexion; any quality, which binds the effect to the cause, and renders the one an infallible consequence of the other. We only find, that the one does actually, in fact, follow the other.
Three paths, all blocked. A priori reasoning falls short, empirical reasoning is circular, and direct observation comes up empty.
So what drives causal reasoning?
At this point, a natural question surfaces: if causal reasoning has no rational foundation, why are humans so remarkably good at it? We make countless causal judgments every day — braking to slow down, opening an umbrella against rain, taking medicine to cure illness — and most of the time, these judgments are correct. If there’s no rational basis, what makes them reliable?
Hume’s answer is unexpected: reliable, yes. But not because of reason.
What drives causal reasoning is not rational argument — it is custom (or habit).
After repeatedly experiencing constant conjunction — events of type A followed by events of type B — custom instills a tendency. When you next encounter A, you automatically expect B. No inference required. No principle invoked. Your mind has been trained by repeated experience into a pattern: see the cause, expect the effect.
And that “necessary connection” we believe exists between events? It’s actually a feeling generated during this habitual process — what Hume calls a “felt determination of the mind.” We become aware of being propelled, by force of habit, from one associated idea to another. Then we project this subjective experience outward onto the world.
Necessary connection is in us, not in things.
This is not a denial that causal reasoning is valuable — it’s extraordinarily useful, and reliable more often than not. But its foundation is habit, not rational certification. The subversive insight is this: our most dependable source of knowledge rests on a foundation that cannot itself be rationally justified.
A three-hundred-year-old distribution shift
Hume’s analysis of causation opens onto an even deeper problem — later known as the “problem of induction” — whose influence extends far beyond philosophy.
The core of it is simple: the inference from “it has always been this way” to “it will continue to be this way” carries no logical guarantee.
You’ve seen ten thousand white swans. Can you conclude “all swans are white”? No. Swan number ten thousand and one might be black — and historically, it was. Europeans discovered black swans upon reaching Australia.
You’ve observed a drug working effectively in a thousand clinical trials. Can you guarantee it will work the thousand-and-first time? No. You’re using past statistical regularities to predict the future — and that prediction relies on the assumption that the future will resemble the past, an assumption that cannot itself be proven.
In the late 20th century, Wolpert and Macready proved the No Free Lunch theorem: averaged across all possible data distributions, no learning algorithm outperforms random guessing. Put differently, no algorithm is superior across “all possible futures” — superiority only holds under specific distributional assumptions.
This is the precise mathematical incarnation of the first horn of Hume’s dilemma (deductive arguments cannot establish the Uniformity Principle). It doesn’t say learning is useless — it says the effectiveness of learning depends on assumptions about data distribution, and those assumptions cannot themselves be derived from data.
The problem of induction looks like a purely philosophical puzzle. But translate it into engineering terms and it says: every system that learns from data — including the one you’re deploying right now — faces the same predicament. Modern generalization theory (PAC learning, VC dimension) does provide guarantees: on new data from the same distribution, performance will likely hold up. But those guarantees are conditional — they assume test data is drawn from the same distribution as training data. And “the future distribution will match the past” is exactly the Uniformity Principle in mathematical dress. Generalization theory doesn’t escape Hume’s predicament — it makes it precise: the guarantees are real, but the premise underlying them cannot itself be proven.
In machine learning terminology: distribution shift is not a bug. It is the structural boundary of inductive reasoning. Generalization theory gives you reliable guarantees inside the boundary; outside it — when the world changes — the guarantees lapse, and you cannot know in advance where the boundary lies.
A Scottish philosopher three centuries ago described a problem you confront every time you deploy a model.
Aristotle gave the world a classification system for causation — tidy, confident, aspiring to exhaust every facet of causality. Hume dismantled that confidence. He didn’t deny that causal reasoning is useful. But he demonstrated that our entire stock of causal “knowledge” is built on habits formed through repeated experience — not on direct apprehension of causal mechanisms.
Constant conjunction. Custom. A felt determination of the mind. That’s all we have.
Which raises a question. If even humans — beings with physical bodies who can directly interact with the world, who can run experiments and push billiard balls — can only rely on constant conjunction for causal reasoning, then what about a system that learns entirely from text? It has never pushed a billiard ball, never been caught in the rain, never slammed on brakes on a wet road. Its entire “understanding” of causation is a statistical byproduct of how humans express causal relationships in writing.
Its predicament is more extreme than the one Hume described.
Further reading
- David Hume, An Enquiry Concerning Human Understanding, Section VII — Hume’s original text on causation, more polished and concise than the earlier Treatise. If you’ll read one primary source, make it this one.
- Judea Pearl & Dana Mackenzie, The Book of Why (2018), Chapter 1 — Pearl reframes Hume’s problem through the “Ladder of Causation,” offering the best on-ramp from philosophy into modern causal inference.
The Ocean of Correlation
Hume proved something unsettling: even humans — equipped with physical bodies and the ability to directly manipulate the world — have never actually observed causation itself. All we have is constant conjunction and habit.
So what happens when you take a system that learns entirely from text?
What next-token prediction actually learns
The training objective of a large language model fits in one sentence: given the preceding context, predict the probability distribution over the next token.
Elegant in its simplicity. But what does this objective function learn?
When the model repeatedly encounters “rain” followed by “slippery” and “slippery” followed by “accident” in its training data, it learns the statistical co-occurrence patterns of these token sequences. The probability of “slippery” following “rain” becomes higher than the probability of “sunny.” This is a statistical fact about text distribution, not a causal judgment about the physical world.
In Hume’s vocabulary: next-token prediction learns constant conjunction at the token level.
“Rain” is followed with high probability by “slippery” — because these two concepts appear in close proximity throughout the training corpus. The model develops a tendency — a habit, if we allow ourselves the word — to expect “slippery” upon encountering “rain.”
The structural parallel to Hume’s account of human causal reasoning is striking. Humans form habitual expectations from constant conjunction and mistake those expectations for causal knowledge. LLMs learn statistical regularities from token co-occurrence and output those regularities dressed in causal narrative.
The difference lies in the available channels. Humans have at least one escape route — you can intervene. You can push the billiard ball yourself and watch what happens. An LLM has no such channel. Its entire experience comes from text. It has never been rained on, never felt brakes lock on wet asphalt. Its entire “grasp” of causal relationships is a statistical byproduct of how humans have described those relationships in writing.
The surprising power of constant conjunction
But honesty demands acknowledging something else: statistical co-occurrence is far more powerful than intuition suggests.
In natural language, causal relationships and statistical correlations overlap heavily. If two things frequently co-occur in human-authored text, there’s a good chance some causal link does exist between them — because humans tend to put related things together when they’re writing about meaningful relationships.
This is why a model that “merely” learns statistical co-occurrence can produce output that closely resembles causal reasoning. It doesn’t need to understand causal mechanisms — it only needs to learn the linguistic patterns humans use when expressing causal relationships. And since humans get causation right most of the time, the model’s “causal narratives” are also right most of the time.
This is not a coincidence, nor is it magic. It is the natural result of statistical co-occurrence operating on high-quality data. Constant conjunction is not a weak signal — in carefully organized human text, it is an extremely strong one.
Where the signal distorts
But “most of the time” is not “always.” And the failures are not random — they have structure.
The rooster problem. A rooster crows before sunrise. If all you can learn from data is correlation, the constant conjunction between crowing and sunrise is enough to suggest “the rooster’s crow causes the sun to rise.” Nobody actually believes this. But shift the scenario to a less intuitive domain — an API metric that always spikes before a service goes down — and the line between “correlated with” and “caused by” becomes much harder to draw.
Simpson’s paradox. A drug appears effective in men and effective in women when tested separately, but ineffective — or even harmful — in the combined data. Or the reverse. This is not a data error — it happens when you fail to control for a confounding variable. Purely correlation-based reasoning will systematically give you the wrong answer in these situations.
Collider structures. Two independent causes both influence a single outcome. When you condition on that outcome (filter your data by it), a spurious correlation appears between the two originally independent causes. This is one of the most classical traps in causal reasoning.
Picture a hiring pipeline. Candidates who reach the final round are either technically exceptional, or exceptional communicators (or both). If you only look at final-round candidates, you’ll observe a negative correlation between technical skill and communication skill — the highly technical ones seem to communicate poorly, and the strong communicators seem technically weaker.
But this isn’t real. In the full candidate pool, the two abilities may be completely independent. The negative correlation is a selection artifact created by the collider variable (“reached the final round”).
This isn’t hypothetical. When LLMs face collider structures, they systematically get the wrong answer — the specific benchmark evidence is laid out in the next article.
These are not edge cases. They are structural blind spots of correlational reasoning — areas that no amount of statistical precision can cover. Not because the data is insufficient, but because correlation as a signal simply lacks the resolution.
Looking at mechanism, not taking sides
Whether LLMs possess genuine causal reasoning ability is an open and active debate among serious researchers.
Some studies find that LLMs perform surprisingly well on certain causal reasoning benchmarks. Others argue that this performance reflects memorized causal knowledge from training data rather than genuine reasoning — pointing out that performance drops significantly when confronted with novel causal structures from after the training cutoff. A preliminary 2025 study used structural causal models to measure the causal structure of LLMs’ internal reasoning, finding that standard LLMs fall substantially short of the ideal causal structure.
This debate is far from settled, and its conclusions will matter for engineering practice. But pending its resolution, one thing can be stated from the mechanism: the pretraining objective — next-token prediction — does not distinguish “B because of A” from “A and B frequently co-occur.” Post-training stages (RLHF, RLVR) introduce additional signals — human preferences, reasoning correctness — that may implicitly encode some causal structure. The research mentioned above does find that RLVR training narrows the gap with ideal causal structure. But even then, the gap remains significant, and you have no mechanistic way to judge whether it’s small enough in the specific case you care about.
In engineering terms: the system in front of you cannot be trusted by default on causal reliability. It may get many causal inferences right — pretraining captures causal signals in statistical co-occurrence, post-training may further sharpen those signals — but you lack a reliable way to tell whether any particular inference is causal reasoning or pattern matching.
The ocean’s edge
The ocean of correlation is vast and useful.
Most everyday tasks don’t require rigorous causal reasoning. “Help me write an email” — the model gives you statistically appropriate phrasing. Good enough. “Complete this line of code” — the model gives you the most common pattern in similar contexts. Usually sufficient. “Summarize this document” — the model extracts the most salient information. No problem.
The reason correlation suffices is not that it equals causation — it’s that in these scenarios, being wrong is cheap.
But the ocean has an edge. When you need to answer why rather than merely what, when you face irreversible decisions, when you need to distinguish “happens to co-occur” from “one causes the other” — you find the water growing shallow, correlation’s resolution no longer sufficient.
You need a ladder — to climb from the ocean’s surface to higher ground.
That ladder has already been built.
Further reading
- Zhizhang Fu et al., “Correlation or Causation: Analyzing the Causal Structures of LLM and LRM Reasoning Process” (2025) — The first study to measure the causal structure inside LLM reasoning using structural causal models. Standard LLMs fall substantially short of the ideal causal structure, while RLVR-trained reasoning models close much of the gap. The methodology matters more than the specific numbers.
The Ladder
How deep is the ocean of correlation? Put differently: if causal reasoning has levels, where does an LLM sit?
This question didn’t get a precise answer until the 2000s. And the person who answered it wasn’t a philosopher — it was a computer scientist named Judea Pearl.
Three rungs
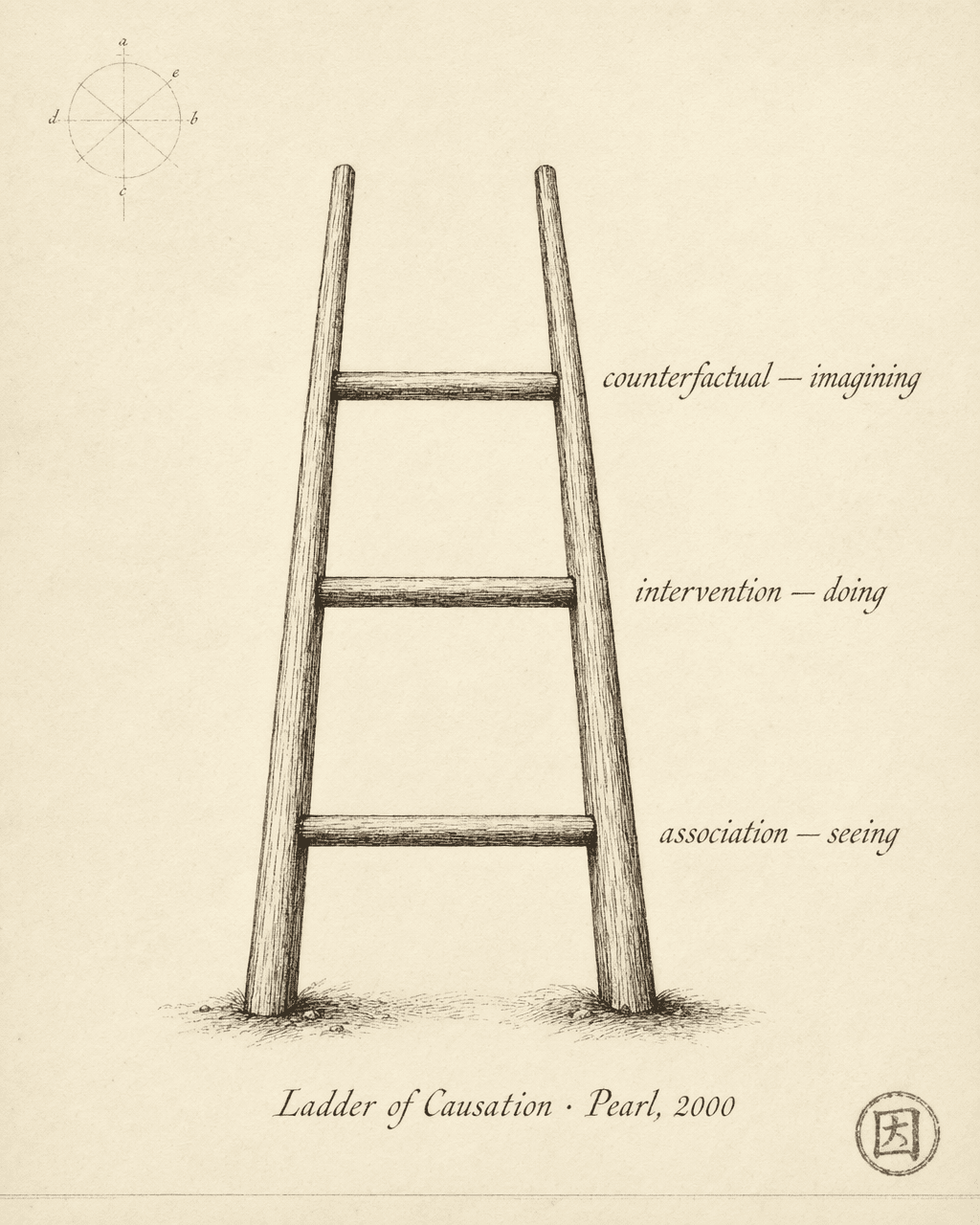
Pearl divided causal reasoning into three levels. He called it the Ladder of Causation.

A single scenario will make the structure clear.
Rung one: Association (Seeing). “Among people who took this drug, 70% recovered.”
This is statistics. You’ve observed a correlation between drug use and recovery in the data. Mathematically, you’re computing P(Y|X) — the probability of Y given that X was observed. No causal assumptions required. Just data and statistical tools. LLMs operate on this rung effortlessly — their entire training process is learning exactly this kind of conditional probability.
Rung two: Intervention (Doing). “If I make a patient take this drug, what is the probability they recover?”
This sounds like the same question. It isn’t.
In the observational data, people who take the drug may already be healthier — they see doctors, fill prescriptions, follow treatment plans. Perhaps it’s this health-consciousness that drives recovery, not the drug itself. This is confounding: a hidden variable simultaneously influences both drug use and recovery, manufacturing a false causal impression.
To answer an interventional question, you need to strip away the confounding. You need not P(Y|X) — the recovery rate among people observed taking the drug — but P(Y|do(X)) — the recovery probability when you make someone take it. Pearl’s do-operator means: not passively observing X, but actively setting X, severing X from all its natural causes.
A randomized controlled trial is the physical realization of the do-operator: random assignment eliminates confounding.
Rung three: Counterfactual (Imagining). “This patient took the drug and recovered. Would they have recovered without the drug?”
This is the highest rung — reasoning about a world that never happened, starting from facts that did. You’re not asking about population statistics. You’re asking about one specific individual’s alternative history.
The legal “but-for” test (would the harm have occurred but for the defendant’s action?) is a counterfactual question. “Did this drug save this person’s life?” is another. Pearl’s framework provides precise mathematical tools for such questions — but it requires a causal model, not merely statistical data.
Why the three rungs cannot substitute for each other
Intuitively, enough first-rung data ought to answer second-rung questions — surely with sufficient observational data, you can tease out causal relationships?
In 2022, Bareinboim, Correa, Ibeling, and Icard proved a theorem that says no.
The three levels of the causal ladder are, in a measure-theoretic sense, almost always separated. Complete knowledge at the first level — meaning knowledge of every statistical association among every variable — is almost always insufficient to determine the answer to a second-level (interventional) question. Similarly, complete knowledge at the first and second levels is almost always insufficient to determine a third-level (counterfactual) answer.
“Almost always” is the mathematical term meaning: exceptions occupy zero measure in the space of possible causal models — the way integers occupy zero measure on the real line. In principle, there exist special cases where first-rung data happens to suffice for a second-rung question. The probability that you encounter one is zero.
This is not an empirical finding. It is a theorem.
Its engineering implication is blunt: no amount of correlational data can answer interventional questions. You could feed every text ever written into a model, let it learn every statistical association among every variable — and those associations would, mathematically, almost always fail to determine what would happen if you did X rather than merely observed X.
Where the LLM sits on the ladder
With this framework in hand, the LLM’s position can be described precisely.
The LLM’s pretraining objective — next-token prediction — structurally corresponds to a first-rung operation. It learns P(next token | context), the conditional probability of the next token given its context. This is an associational task. Post-training stages (RLHF, RLVR) introduce additional optimization signals, but they refine the statistical co-occurrence base that pretraining established — they don’t replace it with a new causal reasoning engine.
Can LLMs, in some sense, “climb” the ladder?
CLadder (2024, NeurIPS) was the first large-scale benchmark designed around Pearl’s three rungs. 10,000 questions with ground-truth answers computed by a formal causal inference engine. Result: LLMs performed best on rung one (association), with significant degradation on rungs two (intervention) and three (counterfactual). A specialized “CausalCoT” prompting strategy helped but could not close the gap.
CausalBench (2024) evaluated LLMs across different causal graph structures. The key finding: LLMs handle chain structures (A→B→C) well — because in chains, correlation and causation align. But they systematically fail on collider structures (A→C←B) — precisely the signature scenario where correlation and causation diverge.
Chi et al. (NeurIPS 2024) drew a further distinction between “level-1 causal reasoning” (recalling causal relationships from parametric knowledge) and “level-2 causal reasoning” (performing genuine causal inference on novel scenarios). Their conclusion: LLMs can only do level-1 — essentially pattern recall, not reasoning. Performance drops markedly when facing causal structures unseen in training data.
Taken together, these findings paint a consistent picture. LLMs can impressively mimic causal language — because their training data is saturated with human expressions of causal relationships. But between mimicry and possession lies a mechanistic chasm, its width guaranteed by the Causal Hierarchy Theorem.
The model can say “rain causes slippery roads” not because it understands the physics of water reducing surface friction, but because it has encountered “rain” and “slippery” in close proximity enough times. Most of the time, the two approaches yield the same answer. But in collider structures, Simpson’s paradox, and confounded scenarios, they part ways.
The ladder and engineering
This is not a judgment about whether LLMs are “smart enough.” It is a structural description of what kind of tool you’re working with.
A screwdriver is not a hammer. That’s not a slight against screwdrivers — it just means that if your task involves driving nails, you need a different tool. Similarly, if your application requires second- or third-rung causal reasoning — distinguishing correlation from causation, answering “what would happen if I did X,” reasoning about counterfactuals — the model alone is insufficient. Something elsewhere in the system needs to bridge the gap.
The ladder tells us what’s missing. But knowing what isn’t enough. The next question is more practical: what does a system that knows its reasoning engine is stuck on the first rung actually need in order to stay honest with itself?
Further reading
- Elias Bareinboim et al., “On Pearl’s Hierarchy and the Foundations of Causal Inference” (2022) — The original paper proving the Causal Hierarchy Theorem. Technically demanding, but the engineering implications of the three-rung separation are profound.
- Zhijing Jin et al., “CLadder: Assessing Causal Reasoning in Language Models” (NeurIPS 2024) — The first benchmark designed around Pearl’s three rungs. If you want concrete data on how LLMs perform at each level, this is the most systematic source.
Causal Discipline
The ladder made the situation clear: LLMs naturally inhabit the first rung — association. Many valuable engineering problems require second- or even third-rung reasoning.
But there’s a subtle pivot here.
The question is not “how do we get the LLM to climb to the second rung.” Maybe that will be possible someday — RLVR training and related approaches are being explored — but it’s not a solved problem today. The more actionable question is: what does a system that knows its reasoning engine can only do first-rung work need in order to remain honest with itself?
The answer doesn’t come from surveying specific engineering practices. It’s derived from the nature of causality itself — from Hume’s analysis, Pearl’s framework, and the mechanistic limitations of the reasoning engine.
Evidence must be graded
Not all “knowing” is equally reliable.
An agent investigating a technical incident reports: “The database latency spike caused the API timeouts.” This statement contains a causal assertion. But what supports it?
If the evidence is “database latency and API timeouts both increased during the same time window” — this is first-rung evidence, an associational observation. Both might be effects of a third cause (network congestion). The causal direction could be entirely backwards.
If the evidence is “we injected artificial database latency in a staging environment and observed API timeouts appear” — this is second-rung evidence, an interventional experiment. Causal direction is now controlled.
If the evidence is “the database team confirmed that a query optimizer regression caused the latency and explained how it propagated to the API layer” — this is expert judgment, typically grounded in understanding of internal mechanisms.
These three forms of “knowing” are not on the same level. The causal ladder directly implies: a system that conflates evidence levels is using the reliability of a correlational observation to bear the weight of a causal assertion.
A system without evidence grading will deliver correlational observations in the tone of causal assertions. The word “caused” sounds identical whether it comes from that system or from a researcher who ran an RCT — but the weight behind the word is entirely different.
The arrow of time must not be violated
Causal relationships have one structural property guaranteed by physics: causes precede effects.
This sounds too obvious to mention. But in the LLM’s world, it’s far from automatic. A model can weave a narrative in any direction — it can say “API timeouts caused the database latency spike” as long as that phrasing is linguistically plausible. Language does not enforce temporal direction.
Among the three elements Hume identified in his analysis of causation, temporal priority is the only purely objective one — it’s not projected by the mind, not produced by habit. It’s a structural constraint of the physical world.
This constraint directly implies: a causal chain in which a cause’s timestamp is later than its effect’s is physically impossible. This is not an optional consistency check — it’s a basic constraint that physics imposes on any causal narrative.
A causal assertion that violates temporal ordering isn’t “possibly wrong” — it’s structurally impossible. An honest system won’t let such assertions pass.
Hypotheses must not skip verification
The core cycle of the scientific method: observation → hypothesis → prediction → verification → accept or reject.
There’s a critical status distinction embedded in this cycle: hypotheses and verified conclusions are not the same thing. The distance between “I suspect database latency caused the timeouts” and “experiments confirmed that database latency caused the timeouts” might be one staging experiment — but it is not zero.
LLMs do not make this distinction. They express hypotheses and conclusions with the same tone, the same certainty. The difference in output probability between “database latency may have caused the timeouts” and “database latency caused the timeouts” is far smaller than the difference in epistemic status.
Epistemic honesty implies: a system that doesn’t distinguish hypotheses from verified conclusions is driving downstream decisions with untested guesses — without knowing it. Hypotheses can exist, can be recorded, can await verification. But the distance between a hypothesis and a conclusion is not zero.
This is not over-engineering. Consider an agent conducting long-chain reasoning that treats an unverified hypothesis as fact, derives conclusions from it, makes decisions based on those conclusions, and takes actions based on those decisions. Every step looks individually reasonable, but the entire chain hangs from an untested hook. This is entropy increase in the reasoning chain — a specific symptom of absent causal discipline.
Reasoning chains must be traceable
Every conclusion should be able to answer the question: “how do you know?”
This is not a rhetorical requirement. In long-chain reasoning, a plausible-looking conclusion may rest on a correlational observation from five steps back — an observation whose causal reliability is limited. If you can’t trace the chain, you can’t evaluate the conclusion’s credibility.
The citation system of scientific publishing is a form of reasoning provenance. Every claim links to its evidence; evidence links to deeper evidence. You can follow the citation chain all the way to original data. This isn’t academic red tape — it’s the structural requirement for making a knowledge system auditable.
Reasoning provenance matters especially for agentic systems. When an agent makes a decision, you need to answer: what did it observe? What inferences did it draw? What was the evidence level at each step? Which links in the chain are strong causal reasoning (experimentally verified) and which are weak (correlational observation) or mere pattern matching?
Without this trace, you’re facing a black box — one that can say “the answer is X” but cannot explain “why X.” For low-risk scenarios, this might be acceptable. For high-risk scenarios, it is not.
The unity of the four disciplines
Step back, and these four are not an independent checklist.
Evidence grading is honesty about how reliable the knowledge is. Temporal ordering is honesty about causal direction. Hypothesis verification is honesty about the degree of confirmation. Reasoning provenance is honesty about the chain of justification.
They are all facets of a single core need — keeping the system honest about what it knows and how it knows it.
This is causal discipline.
Causal discipline is not causal reasoning ability itself — it doesn’t make the system better at inferring causation. It does something more fundamental: it compels the system, when wielding its limited causal reasoning capacity, to remain transparent about the quality of its evidence.
A system without causal discipline presents the most plausible narrative as a factual report. A system with causal discipline annotates: this is a hypothesis based on temporal co-occurrence, evidence level is “associational observation,” causal direction is unverified, reasoning chain is as follows.
The difference is not that the second system is smarter. It’s that the second system is more honest.
Further reading
- Judea Pearl, “An Introduction to Causal Inference” (2010) — Pearl’s own most accessible summary of his framework. Covers SCMs, the do-operator, backdoor and frontdoor criteria, and mediation analysis in about 30 pages. If you want to understand what “causal discipline” looks like in formal terms, start here.
The Cost of Honesty
Causal discipline sounds eminently reasonable — evidence grading, temporal constraints, hypothesis verification, reasoning provenance. Who would object to “making the system more honest”?
But reasonable and free are not the same thing.
Complexity
Every plank of causal discipline adds system complexity.
Evidence grading demands a classification scheme — what counts as “observational” evidence, what counts as “interventional,” what counts as “expert judgment.” These categories must be encoded as types, annotated at every data write, and filtered at every query.
Temporal constraints require timestamp management. Not just “when was this data produced” — but “when did the event this data claims to describe actually occur.” Production time and event time are different. You need two timestamps, consistency checks, and temporal ordering validation whenever a causal chain is assembled.
Hypothesis lifecycle tracking requires a state machine. Every assertion carries a cognitive status — hypothesis, verification-in-progress, confirmed, refuted — with transitions requiring trigger conditions and audit records. Who moved this from “hypothesis” to “confirmed”? Based on what evidence? When?
Reasoning provenance requires graph structures. Each inference links to its premises; premises link to deeper premises. This is not a flat table — it’s a directed acyclic graph. You need to store it, traverse it, and walk it backwards on demand.
A system without causal discipline only needs to store answers. A system with causal discipline needs to store answers, evidence levels, timestamps, cognitive states, reasoning chains, and the update history of all of the above. The data volume and structural complexity are not in the same league.
Speed
Causal discipline slows system response.
Each inference, when produced, needs evidence-level annotation — a classification judgment. Temporal consistency needs checking — a constraint validation. The reasoning chain needs recording — a write operation. Hypothesis status needs checking — a state query.
Each of these steps is fast individually. But they execute on every inference, and long-chain reasoning may involve dozens. Cumulative latency is non-trivial.
More subtly, there’s decision latency. A system without causal discipline can output a conclusion after its first inference. A system with causal discipline may need to wait — because a premise the conclusion depends on is still stuck in “hypothesis” status and needs more evidence before it can be confirmed. The system knows it isn’t sure enough yet, so it waits.
Waiting is the cost of honesty.
Design burden
Causal discipline shifts substantial cognitive load from the model to the system designer.
Who defines the evidence-level taxonomy? How many levels? Where are the boundaries? What level does “the user said so” get? What about “the model inferred it”? Or “extracted from a temporal correlation in logs”?
Who decides when a hypothesis is sufficiently verified? What kind of evidence is enough to promote a hypothesis to a conclusion? How many independent pieces of evidence? At what evidence level? Do the criteria differ across domains?
These questions have no universal answers. Each requires domain expertise and engineering judgment. Causal discipline provides the structure — you need grading, you need verification, you need provenance — but the specific parameters within that structure are the designer’s work.
This is an engineering tradeoff, not a moral judgment. Investing more design effort to achieve higher causal reliability — whether it’s worthwhile depends on the scenario.
When correlation is good enough
Not every scenario needs causal discipline.
“Help me write an email” — the model supplies statistically appropriate phrasing. Wrong? Edit two sentences.
“Complete this line of code” — the model offers the most common pattern for this context. Usually sufficient. Wrong? The compiler and tests will tell you.
“Summarize this document” — the model extracts the most salient information. Missed something? Ask again, or read the original.
These scenarios share a common trait: errors are visible, cheap, and correctable.
When errors are visible, you don’t need causal discipline to ensure correctness — the feedback loop itself corrects mistakes. When errors are cheap, the engineering investment in causal discipline doesn’t pay for itself. When errors are correctable, occasional mistakes carry no irreversible consequences.
In these scenarios, the efficiency advantage of correlational reasoning — fast, lightweight, no elaborate evidence management system required — far outweighs the cost of its occasional failures. Imposing causal discipline would be over-engineering.
When causal discipline is essential
Three conditions push you past correlation’s limits.
Errors are invisible. The agent makes a plausible-looking but incorrect causal judgment, and you have no rapid detection mechanism. The error propagates, compounds, and doesn’t surface until the consequences are already irreversible. This is silent failure — the most dangerous consequence of absent causal discipline in a reasoning chain.
Errors are expensive or irreversible. Medical diagnostic suggestions, financial decision support, root-cause analysis of security incidents — in these scenarios, one wrong causal judgment can mean consequences that cannot be walked back. You cannot rely on “fix it if it’s wrong” — because the cost of fixing dwarfs the benefit of being right.
Reasoning chains are long. This is the most overlooked category. Each reasoning step introduces a small amount of causal uncertainty. In short chains — one or two steps — cumulative error is negligible. But in long chains — ten, twenty, or more steps — uncertainty compounds.
This last point connects directly to the third chapter of this series (Entropy). Information decay in reasoning chains has a specific cause: the silent substitution of correlation for causation at each step. Causal discipline’s core job is to force a signal-quality check at every link — compelling the system to honestly annotate, at each step, how causally reliable this particular inference is.
Three factors — visibility, cost, chain length — form a judgment framework.
| Factor | Low need | High need |
|---|---|---|
| Error visibility | Errors surface quickly | Errors may remain hidden |
| Error cost | Wrong is cheap, can redo | Wrong is expensive or irreversible |
| Chain length | One or two steps to conclusion | Multi-step reasoning, uncertainty compounds |
When all three columns sit on the left, correlation is good enough. When any column moves to the right, causal discipline starts becoming necessary. When multiple columns are simultaneously on the right — a long reasoning chain producing irreversible decisions where errors are hard to detect — causal discipline is not optional. It’s a survival condition.
Further reading
- Haoang Chi et al., “Unveiling Causal Reasoning in Large Language Models: Reality or Mirage?” (NeurIPS 2024) — Distinguishes LLM level-1 (parametric knowledge recall) from level-2 (genuine causal inference) ability, and shows that external scaffolding (G2-Reasoner) significantly improves level-2 performance. An empirical answer to the question of whether the cost of causal discipline is worth paying.
The Dao of Causality
Five articles in, the structure of causal discipline is clear.
Back to the beginning: Hume proved we’ve never observed causation itself — only constant conjunction and habit. LLMs face the same predicament, taken to an extreme — their entire experience is statistical co-occurrence in text. Pearl’s ladder quantified the predicament: first-rung data is mathematically almost always insufficient for second-rung answers. Causal discipline — evidence grading, temporal constraints, hypothesis verification, reasoning provenance — is the engineering response to this predicament.
If that structure is right, certain deeper insights surface naturally.
Feedback loops are causal bets
The second chapter of this series was about cybernetics — the feedback loop at the heart of agent systems: observe → judge → act → observe. The focus then was on the loop’s structure and stability.
Now look at that loop through the lens of causation.
“Observe” implies: I assume my observations reflect the world’s true state. This is a causal claim — that observational data and world state are causally linked.
“Judge” implies: I assume my reasoning correctly identifies causal structure in the observed data. This is a stronger causal claim — I’m not just seeing data, I’m inferring causation from it.
“Act” implies: I assume my intervention will produce the expected outcome. This is a second-rung causal claim — if I do(X), Y will follow.
Every step of the feedback loop contains a causal assertion. It’s not merely an “architectural pattern” — it’s a stack of causal bets. Each iteration of the loop, the system wagers: my observations are accurate, my inferences are correct, my actions are effective.
Most of the time, these bets win. But when they lose — observations are inaccurate, inferences rest on spurious correlations, actions produce unintended consequences — the loop’s behavior becomes unpredictable. This is what “instability” means at the causal level: not that parameters are mistuned, but that causal assumptions are wrong.
Causal discipline’s role within the feedback loop is to make each causal bet explicit — so that at minimum, you know what you’re wagering and how much you’ve staked.
Entropy increase is a symptom of absent causal discipline
The third chapter was about entropy — information decay in long reasoning chains. The focus then was the thermodynamic analogy: disorder naturally increases.
Now that analogy can be given a more precise interpretation.
Information decay in long-chain reasoning has a specific source: the silent substitution of correlation for causation.
Step one of the chain observes “A and B frequently co-occur” — an associational claim. Step two says “A causes B” — silently sliding from the first rung to the second, without the system flagging the transition. Step three derives “therefore controlling A will control B” — an interventional conclusion, built on an unverified causal assumption.
Each “substitution” injects a bit of noise into the reasoning chain. Uncertainty shifts from “how reliable is the correlation I observed?” to “how reliable is the causal relationship I assumed?” — and the latter is strictly more uncertain than the former (the Causal Hierarchy Theorem guarantees this).
The longer the chain, the more noise accumulates. This is entropy increase in the reasoning chain — not an abstract metaphor, but an information-theoretic increase in uncertainty.
One of causal discipline’s core jobs is to force a signal-quality check at every link — annotating “this step is a correlational observation” versus “this step is a causal inference,” and “this hypothesis is verified” versus “this hypothesis is unconfirmed.” It can’t eliminate uncertainty, but it can prevent uncertainty from amplifying silently.
Causal discipline is another fractal
The fifth chapter was about fractals — self-similar structure repeating across scales.
Causal discipline has this property too.
At the level of a single inference: each inference needs evidence-level annotation and a link to its justification.
At the level of a single agent: each output needs a confidence level and a justification chain. The agent’s internal reasoning must maintain hypothesis states and temporal consistency.
At the level of multi-agent orchestration: each agent’s output becomes input for downstream agents — evidence levels must propagate across agent boundaries. A “hypothesis” output by one agent must not transform into “confirmed fact” when received by another. Provenance chains must extend across agents — you need to trace “this final conclusion originated from which agent’s which observation.”
At the system audit level: the entire decision chain’s causal discipline must be inspectable. From trigger to decision to execution, every step’s evidence level and reasoning justification must be completely recorded.
Four scales, same structure. Evidence grading, temporal constraints, hypothesis verification, reasoning provenance — needed at every level, manifesting differently but addressing the same core requirement.
This is no coincidence. The self-similarity of causal discipline and the self-similarity of agentic system architecture (the fifth chapter’s central argument) share the same root: the quality management problem that information faces when passing between scales is structurally identical.
The open question of the carrier
At this point, we know the four components of causal discipline, when it’s needed, what it costs, and how it resonates structurally with the preceding chapters of this series.
But one fundamental question remains untouched.
Causal discipline needs a carrier — a form of computation capable of expressing causal structure, enforcing causal constraints, and maintaining causal chains.
Logic systems are natural fits for the job. Causal graphs can encode causal direction, the do-operator can distinguish observation from intervention, counterfactual reasoning has precise mathematical definitions. Pearl’s entire framework is built on symbolic causal models. But logic systems have a critical weakness: they need humans to encode the causal structure in advance. You have to tell them what causes what — they won’t discover it from data.
Neural networks are natural fits for discovering patterns from data. They can extract the statistical association between “rain” and “slippery” from billions of text passages, and even express that association in causal language. But we’ve spent five articles establishing that what they discover is correlation, not causation.
One excels at structure but not discovery. The other excels at discovery but not structure.
In 2024–2025 research, a clear trend is emerging: using LLMs as a knowledge prior in combination with traditional causal algorithms. The LLM provides “guesses” about possible causal relationships between variables; traditional algorithms (like the PC algorithm) verify whether those guesses are statistically consistent with the data. The combination significantly outperforms either approach used alone.
This is not “getting the LLM to do causal reasoning.” It’s letting the LLM do what it’s good at (extracting linguistic expressions of causal knowledge from text), then using formal tools to do what it’s not good at (verifying whether those expressions are consistent with actual causal structure in the data).
The engineering implementation of causal discipline ultimately has to answer this question: how do structure and discovery — symbolic systems and neural networks — collaborate?
That question’s answer doesn’t belong in this chapter. It belongs to an older divide — one that artificial intelligence has faced since the day it was born: symbolism versus connectionism.
That’s the next chapter’s story.
Further reading
- Shantanu Yanagihara et al., “Failure Modes of LLMs for Causal Reasoning on Narratives” (2024) — Identifies three systematic failure modes in LLM causal reasoning (temporal ordering bias, long-range reasoning collapse, over-reliance on parametric knowledge over context) and finds that forcing the model to extract an explicit causal graph before reasoning significantly mitigates all three. A microcosm of the carrier question in empirical form.